Figure 7.1: Workflow of instrumenting Perl code with dfepl.
Next: Introduction [Contents][Index]
This is the user manual for the Daikon invariant detector. It describes Daikon version 5.8.24, released May 6, 2026.
| • Introduction | ||
| • Installing Daikon | ||
| • Example usage | ||
| • Running Daikon | ||
| • Daikon output | ||
| • Enhancing Daikon output | ||
| • Front ends and instrumentation | ||
| • Tools | ||
| • Troubleshooting | ||
| • Details | ||
| • General Index | ||
Next: Installing Daikon, Previous: Top, Up: Top [Contents][Index]
Daikon is an implementation of dynamic detection of likely invariants; that is, the Daikon invariant detector reports likely program invariants. An invariant is a property that holds at a certain point or points in a program; these are often seen in assert statements, documentation, and formal specifications. Invariants can be useful in program understanding and a host of other applications. Examples include ‘x.field > abs(y)’; ‘y = 2*x+3’; ‘array a is sorted’; for all list objects lst, ‘lst.next.prev = lst’; for all treenode objects n, ‘n.left.value < n.right.value’; ‘p != null => p.content in myArray’; and many more. You can extend Daikon to add new properties (see Enhancing Daikon output, or see New invariants in Daikon Developer Manual).
Dynamic invariant detection runs a program, observes the values that the program computes, and then reports properties that were true over the observed executions. Daikon can detect properties in C, C++, C#, Eiffel, F#, Java, Perl, and Visual Basic programs; in spreadsheet files; and in other data sources. (Dynamic invariant detection is a machine learning technique that can be applied to arbitrary data.) It is easy to extend Daikon to other applications.
Daikon is freely available for download from download-site. Daikon’s license permits unrestricted use (see License). The distribution includes both source code (also available on GitHub) and documentation, Many researchers and practitioners have used Daikon; those uses, and Daikon itself, are described in various publications.
For more information on Daikon, see Introduction in Daikon Developer Manual. For instance, the Daikon Developer Manual indicates how to obtain Daikon’s source code and how to extend Daikon with new invariants, new derived variables, and front ends for new languages. It also contains information about the implementation and about debugging flags.
Next: Example usage, Previous: Introduction, Up: Top [Contents][Index]
Shortcut for the impatient: skip directly to the Installation instructions.
The main way to install Daikon is from a release, as explained in this section. (Alternately, see Source code (version control repository) in Daikon Developer Manual, to obtain the latest Daikon source code from its version control repository.) Here is an overview of the steps.
Details appear below; select the instructions for your operating system.
Differences from previous versions of Daikon appear in the file doc/CHANGELOG.md in the distribution. To be notified of new releases, or to join discussions about Daikon, subscribe to one of the mailing lists (see Mailing lists).
| • Requirements | ||
| • Installation |
Next: Installation, Up: Installing Daikon [Contents][Index]
In order to run Daikon, you must have a Java 8 (or later) JDK, including a Java Virtual Machine and a Java compiler.
If you wish to analyze C or C++ programs, or if you wish to edit the Daikon source code and re-compile Daikon, see Compiling Daikon in Daikon Developer Manual.
Daikon is supported on Unix environments, including Linux, Mac OS X, and Windows Subsystem for Linux (WSL). It is not supported on Windows or Cygwin.
Previous: Requirements, Up: Installing Daikon [Contents][Index]
cd daikonparent wget http://plse.cs.washington.edu/daikon/download/daikon-5.8.24.tar.gz tar zxf daikon-5.8.24.tar.gz
This creates a daikonparent/daikon-5.8.24/ subdirectory.
We will assume that you are using the bash shell or one of its variants. Add commands like these to your ~/.bashrc or ~/.bash_profile file:
# "daikonparentpath" is the absolute path to the directory that contains Daikon.
export DAIKONDIR=daikonparentpath/daikon-5.8.24
source ${DAIKONDIR}/scripts/daikon.bashrc
After editing your shell initialization file, either execute the commands
you placed in it (e.g., run source ~/.bashrc),
or else log out and log back in to achieve the same
effect.
You may customize them by setting environment variables, or by adding a Makefile.user file to directory ${DAIKONDIR}/java (it is automatically read at the beginning of the main Makefile, and prevents you from having to edit the main Makefile directly).
make -C ${DAIKONDIR} rebuild-everything
This builds the various executables used by Daikon, such as the C/C++ front end Kvasir (see Installing Kvasir) and the JDK for use with DynComp (see Instrumenting the JDK with DynComp). If you need more information about compiling Daikon, see Compiling Daikon in Daikon Developer Manual. If you have trouble compiling the C/C++ front end Kvasir, see See Installing Kvasir.
Note that running this make command may take 20 minutes or more, depending on your computer.
Optionally, download other executables, such as the Simplify theorem prover (see Installing Simplify).
Next: Running Daikon, Previous: Installing Daikon, Up: Top [Contents][Index]
Detecting invariants involves two steps:
This section briefly describes how to obtain data traces for Java, C, C#, Perl, and Eiffel programs, and how to run Daikon. For detailed information about these and other front ends that are available for Daikon, see Front ends and instrumentation.
Next: Detecting invariants in C/C++ programs, Up: Example usage [Contents][Index]
Before detecting invariants in Java programs, you must run
make -C ${DAIKONDIR}/java dcomp_rt.jar
(for more details, see Instrumenting the JDK with DynComp).
In order to detect invariants in a Java program, you will run the program twice — once using DynComp (see DynComp for Java) to create a .decls file and once using Chicory (see Chicory) to create a data trace file. Then, run Daikon on the data trace file to detect invariants. With the --daikon option to Chicory, a single command performs the last two steps.
For example, if you usually run
java -cp myclasspath mypackage.MyClass arg1 arg2 arg3
then instead you would run these two commands:
java -cp myclasspath:${DAIKONDIR}/daikon.jar daikon.DynComp mypackage.MyClass arg1 arg2 arg3
java -cp myclasspath:${DAIKONDIR}/daikon.jar daikon.Chicory --daikon \
--comparability-file=MyClass.decls-DynComp \
mypackage.MyClass arg1 arg2 arg3
and the Daikon output is written to the terminal.
| • StackAr example | ||
| • Detecting invariants when running a Java program from a jar file | ||
| • Understanding the invariants | ||
| • Second Java example |
Next: Detecting invariants when running a Java program from a jar file, Up: Detecting invariants in Java programs [Contents][Index]
The Daikon distribution contains some sample programs that will help you get practice in running Daikon.
To detect invariants in the StackAr sample program, perform the following steps after installing Daikon (see Installing Daikon).
cd examples/java-examples/StackAr javac -g DataStructures/*.java
java -cp .:${DAIKONDIR}/daikon.jar daikon.DynComp DataStructures.StackArTester
java -cp .:${DAIKONDIR}/daikon.jar daikon.Chicory --daikon \
--comparability-file=StackArTester.decls-DynComp \
DataStructures.StackArTester
Alternately, replacing the --daikon argument by --daikon-online has the same effect, but does not write a data trace file to disk.
If you wish to have more control over the invariant detection process, you can split the third step above into multiple steps. Then, step 3 would become:
java -cp .:${DAIKONDIR}/daikon.jar daikon.Chicory \
--comparability-file=StackArTester.decls-DynComp \
DataStructures.StackArTester
java -cp ${DAIKONDIR}/daikon.jar daikon.Daikon StackArTester.dtrace.gz
There are various ways to do this.
PrintInvariants program to display the invariants.
java -cp ${DAIKONDIR}/daikon.jar daikon.PrintInvariants StackArTester.inv.gz
For more options to the PrintInvariants program, see Printing invariants.
java -cp .:${DAIKONDIR}/daikon.jar daikon.tools.jtb.Annotate StackArTester.inv.gz \
DataStructures/StackAr.java
Now examine file DataStructures/StackAr.java-escannotated. For more information about the Annotate program, see Annotate.
Daikon can analyze multiple runs (executions) of the program. You can supply Daikon with multiple trace files:
java -cp .:${DAIKONDIR}/daikon.jar daikon.Chicory \
--dtrace-file=StackArTester1.dtrace.gz \
--comparability-file=StackArTester.decls-DynComp DataStructures.StackArTester
java -cp .:${DAIKONDIR}/daikon.jar daikon.Chicory \
--dtrace-file=StackArTester2.dtrace.gz \
--comparability-file=StackArTester.decls-DynComp DataStructures.StackArTester
java -cp .:${DAIKONDIR}/daikon.jar daikon.Chicory \
--dtrace-file=StackArTester3.dtrace.gz \
--comparability-file=StackArTester.decls-DynComp DataStructures.StackArTester
java -cp ${DAIKONDIR}/daikon.jar daikon.Daikon StackArTester*.dtrace.gz
(In this example, all the runs are identical, so multiple runs yield the same invariants as one run.)
Next: Understanding the invariants, Previous: StackAr example, Up: Detecting invariants in Java programs [Contents][Index]
If your Java program is run directly from a jar file, such as either of:
java mypackage.jar arguments java -cp myclasspath mypackage.jar arguments
then to detect invariants in that Java program, run these two commands:
java -cp myclasspath:${DAIKONDIR}/daikon.jar daikon.DynComp <MyMain> arguments
java -cp myclasspath:${DAIKONDIR}/daikon.jar daikon.Chicory --daikon \
--comparability-file=<MyMain>.decls-DynComp <MyMain> arguments
where <MyMain> is the Main-class of the jar file, which you
can determine by running the command:
unzip -p mypackage.jar META-INF/MANIFEST.MF | grep '^Main-Class:'
Next: Second Java example, Previous: Detecting invariants when running a Java program from a jar file, Up: Detecting invariants in Java programs [Contents][Index]
This section examines some of the invariants for the StackAr example. For more help interpreting invariants, see Interpreting output.
The StackAr example is an array-based stack implementation. Take a look at DataStructures/StackAr.java to get a sense of the implementation. Now, look at the sixth section of Daikon output.
====================================================================== StackAr:::OBJECT this.theArray != null this.theArray.getClass().getName() == java.lang.Object[].class this.topOfStack >= -1 this.topOfStack <= size(this.theArray[])-1 ======================================================================
These four annotations describe the representation invariant. The
array is never null, and its run-time type is Object[]. The
topOfStack index is at least -1 and is less than the length
of the array.
Next, look at the invariants for the top() method.
top() has two different exit points, at lines 74 and 75
in the original source. There is a set of invariants for each exit
point, as well as a set of invariants that hold for all exit points.
Look at the invariants when top() returns at line 75.
====================================================================== StackAr.top():::EXIT75 return == this.theArray[this.topOfStack] return == this.theArray[orig(this.topOfStack)] return == orig(this.theArray[post(this.topOfStack)]) return == orig(this.theArray[this.topOfStack]) this.topOfStack >= 0 return != null ======================================================================
The return value is never null, and is equal to the array element at
index topOfStack. The top of the stack is at least 0.
Previous: Understanding the invariants, Up: Detecting invariants in Java programs [Contents][Index]
A second example is located in the examples/java-examples/QueueAr subdirectory. Run this sample using the following steps:
cd examples/java-examples/QueueAr javac -g DataStructures/*.java
java -cp .:${DAIKONDIR}/daikon.jar daikon.DynComp DataStructures.QueueArTester
java -cp .:${DAIKONDIR}/daikon.jar daikon.Chicory --daikon \
--comparability-file=QueueArTester.decls-DynComp \
DataStructures.QueueArTester
Alternately, you can split the very last command into two parts:
java -cp .:${DAIKONDIR}/daikon.jar daikon.Chicory \
--comparability-file=QueueArTester.decls-DynComp \
DataStructures.QueueArTester
java -cp ${DAIKONDIR}/daikon.jar daikon.Daikon QueueArTester.dtrace.gz
Next: Detecting invariants in C# programs, Previous: Detecting invariants in Java programs, Up: Example usage [Contents][Index]
In order to detect invariants over C or C++ programs, you must first install a C/C++ front end (instrumenter). We recommend that you use Kvasir (see Kvasir), and this section gives examples using Kvasir. By default, Kvasir also runs the DynComp tool to improve Daikon’s performance and Daikon’s output by filtering out invariants involving unrelated variables (see DynComp for C/C++).
To use the C/C++ front end Kvasir with your program, first compile your
program.
(If you use gcc to compile your program, use the following
command-line arguments: -gdwarf-3 -no-pie.
Also use -fno-stack-clash-protection if your gcc
supports it.
Note that if your build system separates the
compile and link steps, then -no-pie needs to be on the link
step.)
Then, run your program as usual, but prepend
kvasir-dtrace to the command line.
Kvasir will produce two output files: a .dtrace file containing a trace of a particular execution, and a .decls file that contains information about what variables and functions exist in a program, along with information grouping the variables into abstract types. You will supply both of these files to Daikon.
For more information about Kvasir, including more detailed documentation on its command-line options, see Kvasir.
| • C examples | ||
| • Dealing with large examples |
The Daikon distribution comes with several example C programs to enable users to become familiar with running Daikon on C programs. These examples are located in the examples/c-examples directory.
To detect invariants for a program with Kvasir, you need to perform two basic tasks: run the program under Kvasir to create a trace and declaration files (steps 1–3), and run Daikon over these files to produce invariants (step 4). The following instructions are for the wordplay example, which is a program for finding anagrams.
cd ${DAIKONDIR}/examples/c-examples/wordplay
gcc -gdwarf-3 -no-pie wordplay.c -o wordplay
Kvasir can also be used for programs constructed by compiling a number of .c files separately, and then linking them together; in such a program, specify -gdwarf-3 when compiling each source file containing code you wish to see invariants about.
kvasir-dtrace to the command line.
kvasir-dtrace ./wordplay -f words.txt 'Daikon Dynamic Invariant Detector'
Any options to the program can be specified as usual; here, for instance, we give commands to look for anagrams of the phrase “Daikon Dynamic Invariant Detector” using words from the file words.txt.
Executing under Kvasir, the program runs normally, but Kvasir executes additional checks and collects trace information (for this reason, the program will run more slowly than usual). Kvasir creates a directory named daikon-output under the current directory, and creates the wordplay.dtrace file, which lists variable values, and the wordplay.decls file that contains information about what variables and functions exist in a program, along with information grouping the variables into abstract types.
Kvasir will also print messages if it observes your program doing something with undefined effects; these may indicate bugs in your program, or they may be spurious. (If they are bugs, they can also be tracked down by using Valgrind (https://valgrind.org/) with its regular memory checking tool; if they do not appear with that tool, they are probably spurious).
java -cp ${DAIKONDIR}/daikon.jar daikon.Daikon \
--config_option daikon.derive.Derivation.disable_derived_variables=true \
daikon-output/wordplay.decls daikon-output/wordplay.dtrace
The invariants are printed to standard output, and a binary representation of the invariants is written to wordplay.inv.gz. Note that the example uses a configuration option to disable the use of derived variables; it can also run without that option, but takes significantly longer.
Daikon can analyze multiple runs (executions) of the program. You can supply Daikon with multiple trace files:
kvasir-dtrace --dtrace-file=daikon-output/wordplay1.dtrace \
./wordplay -f words.txt 'daikon dynamic invariant detector'
kvasir-dtrace --no-dyncomp --dtrace-file=daikon-output/wordplay2.dtrace \
./wordplay -f words.txt 'better results from multiple runs'
kvasir-dtrace --no-dyncomp --dtrace-file=daikon-output/wordplay3.dtrace \
./wordplay -f words.txt 'more testing equals better testing'
java -Xmx7g -cp ${DAIKONDIR}/daikon.jar daikon.Daikon \
daikon-output/wordplay*.dtrace daikon-output/wordplay.decls
Note that this example makes the assumption that the DynComp .decls information
for wordplay does not vary from run to run.
Thus it specifies --no-dyncomp on subsequent runs to improve performance.
(This assumption may not be true for other programs.)
Alternatively, you can append information from multiple runs in a single trace file:
kvasir-dtrace --dtrace-file=daikon-output/wordplay-all.dtrace \
./wordplay -f words.txt 'daikon dynamic invariant detector'
kvasir-dtrace --no-dyncomp --dtrace-append \
--dtrace-file=daikon-output/wordplay-all.dtrace \
./wordplay -f words.txt 'better results from multiple runs'
kvasir-dtrace --no-dyncomp --dtrace-append \
--dtrace-file=daikon-output/wordplay-all.dtrace \
./wordplay -f words.txt 'more testing equals better testing'
java -Xmx7g -cp ${DAIKONDIR}/daikon.jar daikon.Daikon \
daikon-output/wordplay-all.dtrace daikon-output/wordplay.decls
PrintInvariants program to display the invariants.
For help understanding the invariants, see Interpreting output.
There is a second example C program in the bzip2 directory.
It may be run in a similar fashion as the wordplay example,
but it is a more complex program and the kvasir-dtrace
step may take several minutes.
Previous: C examples, Up: Detecting invariants in C/C++ programs [Contents][Index]
Since the default memory size used by a Java virtual machine varies, we suggest that Daikon be run with at least 256 megabytes of memory (and perhaps much more). For many JVMs, specify a maximum heap size of 7 GB by using -Xmx7g. For more information about specifying the memory usage for Daikon, see Out of memory.
Disk usage can be reduced by specifying that the front end should compress its output .dtrace files.
In some cases, the time and space requirements of the examples can be reduced by reducing the length of the program run. However, Daikon’s running time depends on both the length of the test run and the size of the program data (such as its use of global variables and nested data structures). The examples also demonstrate disabling derived variables, which significantly improves Daikon’s performance at the cost of producing fewer invariants. For more techniques for using Daikon with large programs and long program runs, see Large dtrace files.
Next: Detecting invariants in Perl programs, Previous: Detecting invariants in C/C++ programs, Up: Example usage [Contents][Index]
The Daikon front end for .NET languages (C#, F#, and Visual Basic) is called Celeriac.
Please see its documentation at https://github.com/codespecs/daikon-dot-net-front-end.
Next: Detecting invariants in Eiffel programs, Previous: Detecting invariants in C# programs, Up: Example usage [Contents][Index]
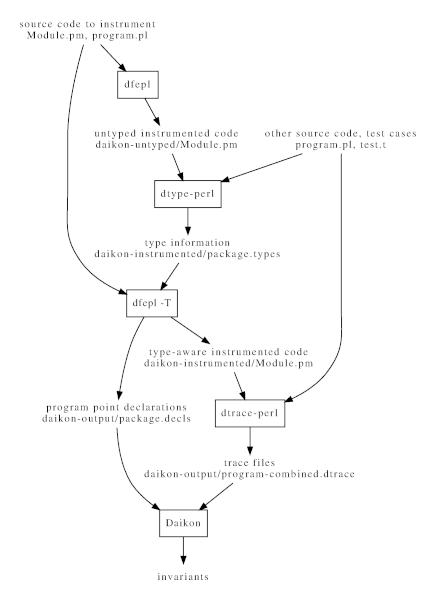
The Daikon front end for Perl is called dfepl.
Using the Perl front end is a two-pass process: first you must run the annotated program so that the runtime system can dynamically infer the kind of data stored in each variable, and then you must re-annotate and re-run the program with the added type information. This is necessary because Perl programs do not contain type declarations.
dfepl requires version 5.8 or later of Perl.
| • Instrumenting Perl programs | ||
| • Perl examples |
Next: Perl examples, Up: Detecting invariants in Perl programs [Contents][Index]
Perl programs must be instrumented twice. First they must be instrumented without type information. Then, once the first instrumented version has been run to produce type information, they must be instrumented again taking the type information into account.
To instrument a stand-alone Perl program, invoke dfepl with
the name of the program as an argument.
dfepl program.pl
To instrument a Perl module or a collection of modules, invoke
dfepl either with the name of each module, or with the name
of a directory containing the modules. To instrument all the modules
in the current directory, give dfepl the argument ..
For instance, if the current directory contains a module
Acme::Trampoline in Acme/Trampoline.pm and another
module Acme::Date in Acme/Date.pm, they can be annotated
by either of the following two commands:
dfepl Acme/Trampoline.pm Acme/Date.pm dfepl .
Once type information is available, run the instrumentation command again with the -T or -t options added to use the produced type information.
For more information about dfepl, see dfepl.
Previous: Instrumenting Perl programs, Up: Detecting invariants in Perl programs [Contents][Index]
The Daikon distribution includes sample Perl programs suitable for use with Daikon in the examples/perl-examples directory.
Here are step-by-step instructions for examining a simple module, Birthday.pm, as used by a test script test-bday.pl.
cd examples/perl-examples
dfepl Birthday.pm
This command creates a directory daikon-untyped, and puts the instrumented version of Birthday.pm into daikon-untyped/Birthday.pm. As the directory name implies, this instrumented version doesn’t contain type information.
dtype-perl test_bday.pl 10
The dtype-perl is a script that runs Perl with the appropriate command line options to find the modules used by the Daikon Perl runtime tracing modules, and to use the instrumented versions of modules in daikon-untyped in preference to their original ones. The number 10 is an argument to the test_bday.pl script telling it to run a relatively short test.
This will also generate a file daikon-instrumented/Birthday.types recording the type of each variable seen during the execution of the instrumented program.
dfepl -T Birthday.pm
This step repeats step 2, except that the -T flag to
dfepl tells it to use the type information generated in the
previous step, and to put the output in the directory
daikon-instrumented. dfepl also converts the
type information into a file daikon-output/Birthday.decls
containing subroutine declarations suitable for Daikon.
dtrace-perl test_bday.pl 30
Here we run another test suite, which happens to be the same
test_bday.pl, but running for longer. (The example will also
work with a smaller number). The script dtrace-perl is
similar to dtype-perl mentioned earlier, but looks for
instrumented source files in daikon-instrumented.
This creates daikon-output/test_bday-combined.dtrace, a trace file containing the values of variables at each invocation. (The file name is formed from the name of the test program, with -combined appended because it contains the trace information from all the instrumented modules invoked from the program).
cd daikon-output
java -cp ${DAIKONDIR}/daikon.jar daikon.Daikon Birthday.decls test_bday-combined.dtrace
PrintInvariants program and other Daikon tools.
For example:
java -cp ${DAIKONDIR}/daikon.jar daikon.PrintInvariants Birthday.inv.gz
Invariants produced from Perl programs can be examined using the same tools as other Daikon invariants.
In the example above, the script test_bday.pl was not itself instrumented; it was only used to test the instrumented code. The Perl front end can also be used to instrument stand-alone Perl programs. The following sequence of commands, similar to those above, show how Daikon can be used with the stand-alone program standalone.pl, also in the examples/perl-examples directory.
dfepl standalone.pl
dtype-perl daikon-untyped/standalone.pl
dfepl -T standalone.pl
dtrace-perl daikon-instrumented/standalone.pl
cd daikon-output
java -cp ${DAIKONDIR}/daikon.jar daikon.Daikon -o standalone.inv standalone-main.decls \
standalone-combined.dtrace
Note two differences when running a stand-alone program. First, the
instrumented versions of the program, in the daikon-untyped or
daikon-instrumented directory, are run directly. Second, the
declarations file is named after the package in which the subroutines
were declared, but since every stand-alone program uses the
main package, the name of the program is prepended to the
.decls file name to avoid collisions.
Next: Detecting invariants in Simulink/Stateflow programs, Previous: Detecting invariants in Perl programs, Up: Example usage [Contents][Index]
CITADEL is an Eiffel front-end to the Daikon invariant detector. You can obtain Citadel from https://se.inf.ethz.ch/people/polikarpova/citadel/.
Previous: Detecting invariants in Eiffel programs, Up: Example usage [Contents][Index]
Hynger (HYbrid iNvariant GEneratoR) instruments Simulink/Stateflow (SLSF) block diagrams to generate Daikon input (.dtrace files). Hynger was created by Taylor Johnson, Stanley Bak, and Steven Drager. You can obtain Hynger from https://github.com/verivital/hynger.
Next: Daikon output, Previous: Example usage, Up: Top [Contents][Index]
This section describes how to run Daikon on a data trace (.dtrace) file, and describes Daikon’s command-line options. This section assumes you have already run a front end (e.g., an instrumenter) to produce a .dtrace file (and optionally .decls and .spinfo files); to learn more about that process, see Example usage, and see Front ends and instrumentation.
Run the Daikon invariant detector via the command
java -cp ${DAIKONDIR}/daikon.jar daikon.Daikon \
[flags] dtrace-files... \
[decls-files...] [spinfo-files...]
Not all Daikon front ends produce .decls files, since program point declarations may also appear in .dtrace files. For instance, the Chicory front end for Java (see Chicory) produces only .dtrace files. If there are no .decls files, then it is not necessary to include them on the command line to Daikon.
Note that using a DynComp generated .decls file as input to Daikon will lead to a decl format error. The correct usage is to use the DynComp generated .decls file(s) as input to Chicory. See Detecting invariants in Java programs for more details.
The files may appear in any order; the file type is determined by whether the file name contains .decls, .dtrace, or .spinfo. As a special case, a file name of - means to read data trace information from standard input.
The optional flags are described in the sections that follow. For further ways to control Daikon’s behavior via configuration options, see Configuration options; also see the list of options to the front ends — such as DynComp (see DynComp for Java options), Chicory (see Chicory options) or Kvasir (see Kvasir options).
| • Options to control Daikon output | ||
| • Options to control invariant detection | ||
| • Processing only part of the trace file | ||
| • Daikon configuration options | ||
| • Daikon debugging options |
Next: Options to control invariant detection, Up: Running Daikon [Contents][Index]
Print usage message.
Output serialized invariants to the specified file; they can later be postprocessed, compared, etc. Default: basename.inv.gz in the current directory, where the first data trace file’s basename starts with basename.dtrace. Default is no serialized output, if no such data trace file was supplied. If a data trace file was supplied, there is currently no way to avoid creating a serialized invariant file.
Don’t print invariants as text output. This option may be used in conjunction with the -o option.
Produce output in the given format. For a list of the output formats supported by Daikon, see Invariant syntax.
Prints (respectively, suppresses) timing information as major portions of Daikon are executed.
Like --show_progress but includes details about invariants.
Suppress the printing of version information
Output numbers of values and samples for invariants and program points; this is a debugging flag. (That is, it helps you understand why Daikon produced the output that it did.)
The ‘Samples breakdown’ output indicates how many samples in the .dtrace file had a modified value (‘m’), had an unmodified value (‘u’), and had a nonsensical value (‘x’). The summary uses a capital letter if the sample had any of the corresponding type of variable, and a lower-case letter if it had none. These types affect statistical tests that determine whether a particular invariant (that was true over all the test runs) is printed.
Only variables that appear in both the pre-state and the post-state (variables that are in scope at both procedure exit and entry) are eligible to be listed as modified or unmodified. This is why the list of all variables is not the union of the modified and unmodified variables.
Read a list of .decls, .dtrace, or .spinfo file names from the given text file, one filename per line, as an alternative to providing the file names on the command line.
Server mode for Daikon in which it reads files from dirname as they appear (sorted lexicographically) until it finds a file ending in ‘.end’, at which point it calculates and outputs the invariants.
Omit some potentially redundant information from the serialized output file produced with -o. By default, the serialized output contains all of the data structures produced by Daikon while inferring invariants. Depending on the use to which the serialized output will later be put, the file can sometimes be significantly shortened by omitting information that is no longer needed. The flag should be followed by one or more characters each representing a kind of structures the can be omitted. The following characters are recognized:
Omit information about program points that were declared, but for which no samples were found in any .dtrace file.
Omit reflexive invariants, those in which a variable appears more
than once.
Usually, such invariants are not interesting, because their meaning is
duplicated by invariants with fewer variables: for instance, x =
x - x and y = z + z can be expressed as x = 0 and
y = 2 * z instead.
However, Daikon generates and uses such invariants internally to
decide what invariants to create when two previously equal variables
turn out to be different.
Omit invariants that are suppressed by other invariants. Suppression refers to a particular optimization in which the processing of an invariant is postponed as long as certain other invariants that logically imply it hold.
For most uses of serialized output in the current version, it is safe to use the 0 and r omissions, but the s omission will cause subtle output changes. In many cases, the amount of space saved is modest (typically around 10%), but the savings can be more substantial for programs with many unused program points, or program points with many variables.
Next: Processing only part of the trace file, Previous: Options to control Daikon output, Up: Running Daikon [Contents][Index]
Set the confidence limit for justifying invariants. If the confidence level for a given invariant is larger than the limit, then Daikon outputs the invariant. This mechanism filters out invariants that are satisfied purely by chance. This is only relevant to invariants that were true in all observed samples; Daikon never outputs invariants that were ever false.
val must be between 0 and 1; the default is .99. Larger values yield stronger filtering.
Each type of invariant has its own rules for determining confidence.
See the computeConfidence method in the Java source code for the
invariant.
For example, consider the invariant a<b whose confidence computation
is 1 - 1/2^numsamples, which indicates the likelihood that the
observations of a and b did not occur by chance. If there were 3
samples, and a<b on all of them, then the confidence would be 7/8 =
.875. If there were 6 samples, and a<b on only 5 on them, the
confidence would be 0. If there were 9 samples, and a<b on all of
them, then the confidence would be 1-1/2^9 = .998.
There are two ways to print the confidence of each invariant. You can use Diff (see Invariant Diff):
java -cp ${DAIKONDIR}/daikon.jar daikon.diff.Diff MyFile.inv.gz
or you can use PrintInvariants
(see Printing invariants):
java -cp ${DAIKONDIR}/daikon.jar daikon.PrintInvariants --dbg daikon.PrintInvariants.repr \
MyFile.inv.gz
To print the confidence of each invariant that is discarded, run Daikon with the --disc_reason all command-line option (see Daikon debugging options).
Indicate that the given class implements the java.util.List
interface. The preferred mechanism for indicating such information is
the ListImplementors section of the .decls file.
See ListImplementors declaration in Daikon Developer Manual.
Use a user-defined invariant that not built into Daikon but
is defined in the given class.
The classname should be in the fully-qualified format expected by
Class.getName(),
such as “mypackage.subpackage.ClassName”,
and its .class file should appear on the classpath.
Disable all known invariants: all those that are built into Daikon, and all those that have been specified by --user-defined-invariant so far. An invariant may be re-enabled after this option is specified, see Options to enable/disable specific invariants.
Avoid connecting program points in a dataflow hierarchy. For example,
Daikon normally connects the :::ENTER program points of class methods
with the class’s :::CLASS program point, so that any invariant
that holds on the :::CLASS program point is considered to hold
true on the :::ENTER
program point. With no hierarchy, each program point is treated
independently. This is for using Daikon on applications that do not
have a concept of hierarchy. It can also be useful when you wish to
process unmatched enter point samples from a trace file that is missing
some exit point samples.
Suppress display of logically redundant invariants, using the Simplify automatic theorem prover. Daikon already suppresses most logically redundant output (this can be controlled by invariant filters; see Invariant filters. For example, if ‘x >= 0’ and ‘x > 0’ are both true, then Daikon outputs only ‘x > 0’. Use of the --suppress_redundant option tells Daikon to use Simplify to eliminate even more redundant output, and should be used if it is important that absolutely no redundancies appear in the output.
The Simplify program must be installed in order to take advantage of this option (see Installing Simplify). Beware that Simplify can run slowly; the amount of effort Simplify exerts for each invariant can be controlled using both the daikon.simplify.Session.simplify_max_iterations and daikon.simplify.Session.simplify_timeout configuration options.
Next: Daikon configuration options, Previous: Options to control invariant detection, Up: Running Daikon [Contents][Index]
Only process program points whose names match the regular expression. The --ppt-omit-pattern argument takes precedence over this argument.
Do not process program points whose names match the regular expression. This takes precedence over the --ppt-select-pattern argument.
Only process variables (whether in the trace file or derived) whose names match the regular expression. The --var-omit-pattern argument takes precedence over this argument.
Ignore variables (whether in the trace file or derived) whose names match the regular expression. This takes priority over the --var-select-pattern argument.
All of the regular expressions used by Daikon use
Java’s regular expression syntax.
Multiple items can be matched by using the logical or operator (‘|’),
for example var1|var2|var3.
Java’s regular expression syntax is similar to Perl’s but
not
exactly the same.
The ...-omit-pattern arguments take precedence: if a name matches an omit pattern, it is excluded. If a name does not match an omit pattern, it is tested against the select pattern (if any). If any select patterns are specified, the name must match one of the patterns in order to be included. If no select patterns are specified, then any ‘ppt’ name that does not match the omit patterns is included.
Using --ppt-select-pattern and --ppt-omit-pattern can save time even if there are no samples for the excluded program points, as Daikon can skip the declarations and need not initialize data structures that would be used if samples were encountered.
Front ends such as Chicory (see Program points in Chicory output)
and Kvasir (see Kvasir options), and other tools such as DynComp
(see DynComp for Java options) and PrintInvariants (see Printing invariants), also support these command-line options (Kvasir names them
slightly differently). Passing the command-line option to the front end
means that the target program will run faster and the trace file will be
smaller.
Next: Daikon debugging options, Previous: Processing only part of the trace file, Up: Running Daikon [Contents][Index]
Load the configuration settings specified in the given file. See Configuration options, for details.
Specify a single configuration setting. See Configuration options, for details.
Previous: Daikon configuration options, Up: Running Daikon [Contents][Index]
Also see configuration options related to debugging (see Debugging options).
These debugging options cause output to be written to a log file (by
default, to the terminal); in other words, they enable a Logger.
The --dbg category option
enables debugging output (logging output) for a specific part of Daikon; it may be
specified multiple times, permitting fine-grained control over debugging
output. The --debug option turns on all debugging flags.
(This produces a lot of output!) Most categories are class or
package names in the Daikon implementation, such as daikon.split
or daikon.derive.binary.SequencesJoin. Only classes that check
the appropriate categories are affected by the debug flags; you can
determine this by looking for a call to Logger.getLogger in
the specific class.
Turns on debugging information on the specified class, variables, and program point. In contrast to the --dbg option, track logging follows a particular invariant through Daikon. Multiple --track options can be specified. Each item (class, variables, and program point) is optional. Multiple classes can be specified separated by vertical bars (‘|’). Matching is a simple substring (not a regular expression) comparison. Each item must match in order for a printout to occur. For more information, see Track logging in Daikon Developer Manual.
Prints all discarded invariants of class inv_class at the program point specified that involve exactly the variables given, as well as a short reason and discard code explaining why they were not worthy of print. Any of the three parts of the argument may be made a wildcard by excluding it. For example, ‘inv_class’ and ‘<var1,var2,...>@ppt’ are valid arguments. Some concrete examples are ‘Implication<x,y>@foo():::EXIT’, ‘<x,y>@foo():::EXIT’, and ‘Implication<x,y>’. To print all discarded invariants, use the argument ‘all’.
Prints memory usage statistics into a file named stat.out in the current directory.
Next: Enhancing Daikon output, Previous: Running Daikon, Up: Top [Contents][Index]
Daikon outputs the invariants that it discovers in textual form to your terminal. This chapter describes how to interpret those invariants — in other words, what do they mean?
Daikon also creates a .inv file that contains the invariants in serialized (binary) form. You can use the .inv file to print the invariants (see Printing invariants) in a variety of formats, to insert the invariants in your source code (see Annotate), to perform run-time checking of the invariants (see Runtime-check instrumenter, and InvariantChecker), and to do various other operations. See Tools, for descriptions of such tools.
If you wish to write your own tools for processing invariants, you have
two general options. You can parse Daikon’s textual output, or you can
write Java code that processes the .inv file. The .inv
file is simply a serialized
PptMap
object. In addition to reading the Javadoc, you can examine how the
other tools use this data structure.
| • Invariant syntax | ||
| • Program points | ||
| • Variable names | ||
| • Interpreting output | ||
| • Invariant list | ||
| • Invariant filters |
Next: Program points, Up: Daikon output [Contents][Index]
Daikon can produce output in a variety of formats. Each of the format
names can be specified as an argument to the --format argument
of Daikon (see Options to control Daikon output), PrintInvariants
(see Printing invariants), and Annotate (see Annotate).
When passed on the command line, the format names are case-insensitive:
--format JML and --format jml have the same effect.
You can enhance Daikon to produce output in other formats. See New formatting for invariants in Daikon Developer Manual.
Daikon’s default format is a mix of Java, mathematical logic, and some additional extensions. It is intended to concisely convey meaning to programmers.
This format produces output in the design-by-contract (DBC) format
expected by Parasoft’s Jtest tool (https://www.parasoft.com).
The Extended Static Checker for Java (ESC/Java) is a programming tool
for finding errors in Java programs by checking annotations that are
inserted in source code; for more details, see
https://www.hpl.hp.com/downloads/crl/jtk/. Daikon’s ESC/Java format
(which can also be specified as ESC format) is intended for use with the
original ESC/Java tool. Use Daikon’s JML format for use with the
ESC/Java2
tool.
Write output as Java expressions. This means that each invariant is a valid Java expression, if inserted at the correct program point: right after method entry, for method entry invariants; right before method exit, for method exit invariants; or anywhere in the code, for object invariants.
There are two exceptions. Method exit invariants that refer to ‘pre-state’, such as ‘x == old(x) + 1’, are output with the tag ‘\old’ surrounding the ‘pre-state’ expression (e.g. ‘x == \old(x) + 1’. Method exit invariants that refer to the return value of the method, such as ‘return == x + y’, are output with the tag ‘\result’ in place of the return value (e.g. ‘\result == x + y’). These expression are obviously not valid Java code.
Produces output in JML (Java Modeling Language, https://www.cs.ucf.edu/~leavens/JML/); for details, see the JML Manual. JML format lets you use the various JVM tools on Daikon invariants, including run-time assertion checking and the ESC/Java2 tool.
Produces output in the format expected by the Simplify automated theorem prover; for details, see the Simplify distribution.
Produces C# output for use with Microsoft’s Code Contracts https://www.microsoft.com/en-us/research/project/code-contracts/. The format employs some extension/utility methods to improve contract readability; the library containing these methods can be found at https://github.com/twschiller/daikon-code-contract-extensions.
Next: Variable names, Previous: Invariant syntax, Up: Daikon output [Contents][Index]
A program point is a specific place in the source code, such as immediately before a particular line of code. Daikon’s output is organized by program points.
For example, foo():::ENTER is the point at the entry to procedure
foo(); the invariants at that point are the preconditions for the
foo() method, properties that are always true when the procedure
is invoked.
Likewise, foo():::EXIT is the program point at the procedure
exit, and invariants there are postconditions. When there are multiple
exit points from a procedure (for instance, because of multiple
return statements), the different exits are differentiated by
suffixing them with their line numbers; for instance,
StackAr.top():::EXIT79. The exit point lacking a line number (in
this example, StackAr.top():::EXIT) collects the postconditions
that are true at every numbered exit point. This is an example of a
program point that represents a collection of locations in the program
source rather than a single location. This concept is represented in
Daikon by the dataflow hierarchy, see
Dataflow hierarchy in Daikon Developer Manual.
The Java instrumenter Chicory selects names for program
points that include an indication of the argument and return types for
each method. These signatures are presented in Class.getName format: one
character for each primitive type (‘B’ for byte, ‘C’ for
character, ‘Z’ for boolean, etc.);
‘Lclassname;’ for object types; and a ‘[’
prefix for each level of array nesting.
| • OBJECT and CLASS program points |
Up: Program points [Contents][Index]
Two program point tags that have special meaning to Daikon’s hierarchy
organization are :::OBJECT and :::CLASS.
The :::OBJECT tag indicates object invariants (sometimes called
representation invariants or class invariants) over all the instance
(member) fields and static fields of the class. These properties always hold
for any object of the given class, from the point of view of a client or
user. These properties hold at entry to and exit from every public
method of the class (except not the entry to constructors, when fields
are not yet initialized).
The :::CLASS tag is just like :::OBJECT, but only for
static variables, which have only one value for all objects. Static
fields and instance fields are often used for different purposes.
Daikon’s separation of the two types of fields permits programmers to
see the properties over the static fields without knowing which are the
static fields and pick them out of the :::OBJECT program point.
(By contrast, ESC/Java and JML make class invariants hold even at the entry and exit of private methods. Their designers believe that most private methods preserve the class invariant and are called only when the class invariant holds. ESC/Java and JML require an explicit helper annotation to indicate a private method for which the class invariant does not hold.)
A trace file does not contain samples for the :::OBJECT and
:::CLASS program points. Variable values for these artificial
program points are constructed from samples that do appear in a trace file.
For example, an object invariant is a property that holds at entry to and
exit from every public method of the class, so the :::OBJECT program
point is constructed from samples at those points.
Next: Interpreting output, Previous: Program points, Up: Daikon output [Contents][Index]
A front end produces a trace file that associates trace variable names with values. Trace variable names need not be exactly the same as the variables in the program. The trace may contain values that are not held in any program variables; in this case, the front end must make up a name to express that value (see below for examples).
Daikon ignores variable names when inferring invariants; it uses the
names only when performing output. (Thus, the only practical
restriction on trace names is that the VarInfoName parse method
must be able to parse the name.)
By convention, trace variables are similar to program variables and
field accesses. For example, w and x.y.z are legal trace
variables. (So are ‘a[i]’, and
‘a[0].next’, but these are usually handled as derived variables
instead; see below.) As in languages such as
Java and C, a period character represents field access and square
brackets represent selecting an element of a sequence.
In addition to variables that appear in the trace file, Daikon creates
additional variables, called derived variables, by combining trace
variables. For example, for any array a and integer i,
Daikon creates a derived variable a[i]. This is not a variable
in the program (and this expression might not even appear in the source
code), but it may still be useful to compute invariants over this
expression. For a list of derived variables and how to control Daikon’s
use of them, see Options to enable/disable derived variables.
Some trace variables and derived variables may represent meaningless expressions; in such a circumstance, the value is said to be nonsensical (see Nonsensical values in Daikon Developer Manual).
The remainder of this section describes conventions for naming expressions. Those that cannot be named by simple C/Java expressions are primarily related to arrays and sequences. (In part, these special expressions are necessary because Daikon can only handle variables of scalar (integer, floating-point, boolean, String) and array-of-scalar types. Daikon cannot handle structs, classes, or multidimensional arrays or structures, but such data structures can be represented as scalars and arrays by choosing variable names that indicate their relationship.)
a[i] array access.
a and i are themselves
arbitrary variable names, of array and integral type, respectively.
a[-1] from-end array access.
a[-1] denotes the last element of array a;
it is syntactic sugar for a[a.length-1].
a[] array contents.
For array-valued expression a, all of its elements, as a
sequence. Simply using the expression a means the identity
(address or hashcode) of the array, not a list of its elements. For two
arrays a and b, ‘a=b’ implies ‘a[]=b[]’, but
‘a[]=b[]’ does not imply ‘a=b’.
x.y, x->y field access.
When field access is applied to a structure/class, it has the usual
meaning of selecting one field from the structure/class.
When field access is applied to an array, it means to map the field
access across the elements of the array. For example, if a is an
array, then a[].foo is the sequence consisting of the foo
fields of each of the elements of a. Likewise,
a[].foo.bar contains the bar fields of a[].foo. By
contrast, a.foo does not make sense, because one cannot ask for
the foo field of an address, and a[].foo[] would be a
two-dimensional array.
x.getClass() is the run-time type of x, which may
differ from its declared type.
a.length is the length (number of elements) of array a;
this is not necessarily the number of initialized or used elements.
s.toString is the string value of String s, namely a
sequence of characters.
Classname.varname static class variable.
Static variables of a class have names of the form
‘classname.varname’
orig(x) refers to the value of variable x upon
entry to a procedure (because the procedure body might modify the value
of x). These variables appear only at :::EXIT program
points. Typically, orig() variables do not appear in the trace,
but are automatically created by Daikon when it matches up
:::ENTER and :::EXITnn program points.
See orig variable example.
This variable prints as orig when using Daikon output format
(see Invariant syntax), but may print differently in other formats
(such as \old).
post(x) refers to the value of variable x upon exit from a
procedure. Such a value is usually written simply x; the
post prefix is needed only within an orig expression, when
the post-state value needs to be referenced. Just as orig may
be used only in a post-state context and specifies an expression to be
evaluated in the ‘pre-state’, post may be used only in a
‘pre-state’ context and specifies an expression to be evaluated in the
post-state. See orig variable example.
/globalVar C global variable. In C output, global variables with
external linkage are
prefixed with a slash. For instance, global /x is distinct from
procedure parameter /x. (In Java programs, variables can be
distinguished by prefixing them with this. or, for class-static
variables, a class name.)
myfile_c/staticVar C static variable. In C output, file-static
variables have names of the form ‘filename/varname’,
where periods (‘.’) in the filename are converted into underscores
(‘_’). For example, ‘Global_c/x’ is the name for a
file-static variable x declared in the file Global.c).
myfile_c@funcname/funcStaticVar C function-scoped static variable.
In C output, for static variables which are
declared within functions, an at-sign ‘@’ separates the filename
and the function name and then a slash separates the function name and
variable name (e.g., ‘Global_c@main/funcStaticVar’ for a static
variable funcStaticVar declared within the function main
in the file Global.c).
Daikon’s current front ends do not produce output for local variables, only for variables visible from outside a procedure. (Also see the --std-visibility option to Chicory, Chicory options.) More generally, Daikon’s front ends produce output at procedure exit and entry, not within the procedure. Thus, Daikon’s output forms a specification from the view of a client of a procedure. If you wish to compute invariants over local variables, you can extend one of Daikon’s front ends (or request us to do so). An alternative that permits computing invariants at arbitrary locations is to call a dummy procedure, passing all the variables of interest. The dummy procedure’s pre and postconditions will be identical and will represent the invariants at the point of call.
The array introduction operator [] can made Daikon variables look
slightly odd, but it is intended to assist in interpreting the variables
and to provide an indication that the variable name cannot be
substituted directly in a program as an expression.
Each array introduction operator [] increases the dimensionality
of the variable, and each array indexing operation [i] decreases
it. Since all Daikon variables are scalars or one-dimensional arrays,
these operators must be matched up, or have at most one more []
than [i]. (There is one exception: according to a strict
interpretation of the rules, the C/Java expression a[i] would
turn into the Daikon variable a[][i], since it does not change
the dimensionality of any expression it appears in. However, that would
be even more confusing, and the point is to avoid confusion, so by
convention Daikon front ends use just a[i], not a[][i].
Strictly speaking, none of the [] operators is necessary, since a
user with a perfect knowledge of the type of each program variable and
field could use that to infer the type of any Daikon expression.)
| • orig variable example |
Up: Variable names [Contents][Index]
This section gives an example of use of orig() and post()
variables and arrays.
Suppose you have initially that (in Java syntax)
int i = 0;
int[] a = new int[] { 22, 23 };
int[] b = new int[] { 46, 47 };
and then you run the following:
// pre-state values at this point a[0] = 24; a[1] = 25 a = b; a[0] = 48; a[1] = 49; i = 1; // post-state values at this point
The values of various variables are as follows:
orig(a[i]) = 22The value of a[i] in the ‘pre-state’: {22, 23}[0]
orig(a[])[orig(i)] = 22This is the same as orig(a[i]): {22, 23}[0].
orig(a[])[i] = 23The value of a[] in the ‘pre-state’ (which is an array object, not
a reference), indexed by the post-state value of i: {22, 23}[1]
orig(a)[orig(i)] = 24orig(a) is the original value of the reference a, not
a's original elements: {24, 25}[0]
orig(a)[i] = 25The original pointer value of a, indexed by the post-state value of i: {24, 25}[1]
a[orig(i)] = 48In the post-state, a indexed by the original value of
i: {48, 49}[0]
a[i] = 49The value of a[i] in the post-state.
b = orig(b) = some hashcodeThe identity of the array b has not changed.
b[] = [48, 49]orig(b[]) = [46, 47]For an array b, ‘b=orig(b)’ does not imply ‘b[]=orig(b[])’.
orig(a[post(i)]) = 23The ‘pre-state’ value of a[1] (because the post-state value of
i is 1): {22, 23}[1]
Next: Invariant list, Previous: Variable names, Up: Daikon output [Contents][Index]
If nothing gets printed before the ‘Exiting’ line, then Daikon found no invariants. You can get a little bit more information by using the --output_num_samples flag to Daikon (see Options to control Daikon output).
Daikon’s output is predicated on the assumption that all expressions that get evaluated are sensible. For instance, if Daikon prints ‘a.b == 0’, then that means that if ‘a.b’ is sensible (that is, ‘a’ is non-null), then its value is zero. When ‘a’ is ‘null’, then ‘a.b’ is called nonsensical. Daikon’s output ignores all nonsensical values. If you would like the assumptions to be printed explicitly, then set the daikon.Daikon.guardNulls configuration option (see General configuration options).
| • Redundant invariants | ||
| • Equal variables | ||
| • Has only one value variables | ||
| • Object inequality |
Next: Equal variables, Up: Interpreting output [Contents][Index]
By default, Daikon does not display redundant invariants — those
that are implied by other invariants in the output — because such
results would merely clutter the output without adding any valuable
information. For instance, if Daikon reports ‘x==y’, then it never
also reports ‘x-1==y-1’. You can control this behavior to some extent by
disabling invariant filters; see Invariant filters.
(You can also print all invariants, even
redundant ones, by saving the invariants to a .inv file and
then using the PrintInvariants (see Printing invariants) or Diff
(see Invariant Diff) programs to print the results.)
Next: Has only one value variables, Previous: Redundant invariants, Up: Interpreting output [Contents][Index]
If two variables x and y are equal, then any invariant
about x is also true about y. Daikon chooses one variable
(the leader) from the set of equal variables, and only prints invariants
over the leader.
Suppose that a = b = c. Then Daikon will print a = b and
a = c, but not b = c. Furthermore, Daikon might print
a > d, but would not print b > d or c > d.
You can control which variables are in an equality set; see Variable comparability in Daikon Developer Manual.
Next: Object inequality, Previous: Equal variables, Up: Interpreting output [Contents][Index]
The output ‘var has only one value’ in Daikon’s output means that every time that variable var was encountered, it had the same value. Daikon ordinarily reports the actual value, as in ‘var == 22’. Typically, the “has only one value” output means that the variable is a hashcode or address — that is, its declared type is ‘hashcode’ (see Variable declarations in Daikon Developer Manual). For example, ‘var == 0x38E8A’ is not very illuminating, but it is still interesting that var was never rebound to a different object.
Note that ‘var has only one value’ is different from saying that var is unmodified.
A variable might have only one value but not be reported as unmodified because the variable is not a parameter to a procedure — for instance, if a routine always returns the same object, or in a class invariant. A variable can be reported as unmodified but not have only one value because the variable is never modified during any execution of the procedure, but has different values on different invocations of the procedure.
Previous: Has only one value variables, Up: Interpreting output [Contents][Index]
Daikon may report ‘x < y’ where the operator ‘<’ is not applicable to the type of ‘x’ and ‘y’, as in ‘myString < otherString’.
In this case, the invariant means that the first expression is always less than the second, according to the ‘Comparable.compareTo’ method.
Next: Invariant filters, Previous: Interpreting output, Up: Daikon output [Contents][Index]
The following is a list of all of the invariants that Daikon detects. Each invariant has a configuration enable switch. By default most invariants are enabled. Any that are not enabled by default are indicated below. Some invariants also have additional configuration switches that control their behavior. These are indicated below as well. See Options to enable/disable specific invariants.
This is a special invariant used internally by Daikon to represent an antecedent invariant in an implication where that antecedent consists of two invariants anded together.
Represents sequences of double values that contain a common subset. Prints as
{e1, e2, e3, ...} subset of x[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.CommonFloatSequence.enabled’.
See also the following configuration option:
Represents sequences of long values that contain a common subset. Prints as
{e1, e2, e3, ...} subset of x[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.CommonSequence.enabled’.
See also the following configuration option:
Represents string sequences that contain a common subset. Prints as {s1, s2, s3, ...}
subset of x[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.stringsequence.CommonStringSequence.enabled’.
Tracks every unique value and how many times it occurs. Prints as either x has no values
or as x has values: v1 v2 v3 .... The set has no maximum size; it may be arbitrarily
large.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.scalar.CompleteOneOfScalar.enabled’.
Tracks every unique value and how many times it occurs. Prints as either x has no values
or as x has values: "v1" "v2" "v3" .... The set has no maximum size; it may be
arbitrarily large.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.string.CompleteOneOfString.enabled’.
This is a special invariant used internally by Daikon to represent invariants whose meaning Daikon doesn’t understand. The only operation that can be performed on a DummyInvariant is to print it. In particular, the invariant cannot be tested against a sample: the invariant is always assumed to hold and is always considered to be statistically justified.
The main use for a dummy invariant is to represent a splitting condition that appears in a
.spinfo file. The .spinfo file can indicate an arbitrary Java expression, which
might not be equivalent to any invariant in Daikon’s grammar.
Ordinarily, Daikon uses splitting conditions to split data, then seeks to use that split data
to form conditional invariants out of its standard built-in invariants. If you wish the
expression in the .spinfo file to be printed as an invariant, whether or not it is itself
discovered by Daikon during invariant detection, then the configuration option daikon.split.PptSplitter.dummy_invariant_level must be set, and formatting information must be
supplied in the splitter info file.
Represents the invariant that each element of a sequence of long values is greater than or
equal to a constant. Prints as x[] elements >= c.
See also the following configuration options:
Represents the invariant that each element of a sequence of double values is greater than or
equal to a constant. Prints as x[] elements >= c.
See also the following configuration options:
Represents the invariant "x != 0" where x represents all of the elements of a sequence of
long. Prints as x[] elements != 0.
Represents the invariant "x != 0" where x represents all of the elements of a sequence of
double. Prints as x[] elements != 0.
Represents sequences of long values where the elements of the sequence take on only a
few distinct values. Prints as either x[] elements == c (when there is only one value),
or as x[] elements one of {c1, c2, c3} (when there are multiple values).
May print as x[] elements has only one value when x is an array of hashcodes
(pointers) – this is because the numerical value of the hashcode (pointer) is uninteresting.
See also the following configuration options:
Represents sequences of double values where the elements of the sequence take on only a
few distinct values. Prints as either x[] elements == c (when there is only one value),
or as x[] elements one of {c1, c2, c3} (when there are multiple values).
See also the following configuration option:
Represents sequences of String values where the elements of the sequence take on only a
few distinct values. Prints as either x[] elements == c (when there is only one value),
or as x[] elements one of {c1, c2, c3} (when there are multiple values).
See also the following configuration option:
Internal invariant representing double scalars that are equal to minus one. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Internal invariant representing double scalars that are equal to one. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Internal invariant representing double scalars that are equal to zero. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Internal invariant representing double scalars that are greater than or equal to 64. Used for non-instantiating suppressions. Will never print since Bound accomplishes the same thing.
Internal invariant representing double scalars that are greater than or equal to 0. Used for non-instantiating suppressions. Will never print since Bound accomplishes the same thing.
Internal invariant representing longs whose values are always 0 or 1. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Internal invariant representing longs whose values are between 0 and 63. Used for non-instantiating suppressions. Will never print since Bound accomplishes the same thing.
Internal invariant representing long scalars that are equal to minus one. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Internal invariant representing long scalars that are equal to one. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Internal invariant representing long scalars that are equal to zero. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Invariant representing longs whose values are always even. Used for non-instantiating
suppressions. Since this is not covered by the Bound or OneOf invariants it is printed. Prints
as x is even.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.EltRangeInt.Even.enabled’.
Internal invariant representing long scalars that are greater than or equal to 64. Used for non-instantiating suppressions. Will never print since Bound accomplishes the same thing.
Internal invariant representing long scalars that are greater than or equal to 0. Used for non-instantiating suppressions. Will never print since Bound accomplishes the same thing.
Invariant representing longs whose values are always a power of 2 (exactly one bit is set).
Used for non-instantiating suppressions. Since this is not covered by the Bound or OneOf
invariants it is printed. Prints as x is a power of 2.
Represents the invariant that each element of a sequence of long values is less than or
equal to a constant. Prints as x[] elements <= c.
See also the following configuration options:
Represents the invariant that each element of a sequence of double values is less than or
equal to a constant. Prints as x[] elements <= c.
See also the following configuration options:
Represents equality between adjacent elements (x[i], x[i+1]) of a double sequence. Prints as
x[] elements are equal.
Represents the invariant >= between adjacent elements
(x[i], x[i+1]) of a double sequence. Prints as
x[] sorted by >=.
Represents the invariant > between adjacent elements
(x[i], x[i+1]) of a double sequence. Prints as
x[] sorted by >.
Represents the invariant <= between adjacent elements
(x[i], x[i+1]) of a double sequence. Prints as
x[] sorted by <=.
Represents the invariant < between adjacent elements
(x[i], x[i+1]) of a double sequence. Prints as
x[] sorted by <.
Represents equality between adjacent elements (x[i], x[i+1]) of a long sequence. Prints as
x[] elements are equal.
Represents the invariant >= between adjacent elements
(x[i], x[i+1]) of a long sequence. Prints as
x[] sorted by >=.
Represents the invariant > between adjacent elements
(x[i], x[i+1]) of a long sequence. Prints as
x[] sorted by >.
Represents the invariant <= between adjacent elements
(x[i], x[i+1]) of a long sequence. Prints as
x[] sorted by <=.
Represents the invariant < between adjacent elements
(x[i], x[i+1]) of a long sequence. Prints as
x[] sorted by <.
Keeps track of sets of variables that are equal. Other invariants are instantiated for only one
member of the Equality set, the leader. If variables x, y, and z are
members of the Equality set and x is chosen as the leader, then the Equality will
internally convert into binary comparison invariants that print as x == y and x ==
z.
Represents an invariant of == between two double scalars. Prints as x == y.
Represents an invariant of >= between two double scalars. Prints as x >= y.
Represents an invariant of > between two double scalars. Prints as x > y.
Represents an invariant of <= between two double scalars. Prints as x <= y.
Represents an invariant of < between two double scalars. Prints as x < y.
Represents an invariant of != between two double scalars. Prints as x != y.
Represents the invariant x = BitwiseAnd(y, z) over three long
scalars.
Since the function is symmetric, only the permutations xyz, yxz, and zxy are checked.
Represents the invariant x = BitwiseOr(y, z) over three long
scalars.
Since the function is symmetric, only the permutations xyz, yxz, and zxy are checked.
Represents the invariant x = BitwiseXor(y, z) over three long
scalars.
Since the function is symmetric, only the permutations xyz, yxz, and zxy are checked.
Represents the invariant x = Division(y, z) over three long
scalars.
Since the function is non-symmetric, all six permutations of the variables are checked.
Represents the invariant x = Gcd(y, z) over three long
scalars.
Since the function is symmetric, only the permutations xyz, yxz, and zxy are checked.
Represents the invariant x = LogicalAnd(y, z) over three long
scalars. For logical operations, Daikon treats 0 as false and all other values as true.
Since the function is symmetric, only the permutations xyz, yxz, and zxy are checked.
Represents the invariant x = LogicalOr(y, z) over three long
scalars. For logical operations, Daikon treats 0 as false and all other values as true.
Since the function is symmetric, only the permutations xyz, yxz, and zxy are checked.
Represents the invariant x = LogicalXor(y, z) over three long
scalars. For logical operations, Daikon treats 0 as false and all other values as true.
Since the function is symmetric, only the permutations xyz, yxz, and zxy are checked.
Represents the invariant x = Lshift(y, z) over three long
scalars.
Since the function is non-symmetric, all six permutations of the variables are checked.
Represents the invariant x = Maximum(y, z) over three long
scalars.
Since the function is symmetric, only the permutations xyz, yxz, and zxy are checked.
Represents the invariant x = Minimum(y, z) over three long
scalars.
Since the function is symmetric, only the permutations xyz, yxz, and zxy are checked.
Represents the invariant x = Mod(y, z) over three long
scalars.
Since the function is non-symmetric, all six permutations of the variables are checked.
Represents the invariant x = Multiply(y, z) over three long
scalars.
Since the function is symmetric, only the permutations xyz, yxz, and zxy are checked.
Represents the invariant x = Power(y, z) over three long
scalars.
Since the function is non-symmetric, all six permutations of the variables are checked.
Represents the invariant x = RshiftSigned(y, z) over three long
scalars.
Since the function is non-symmetric, all six permutations of the variables are checked.
Represents the invariant x = RshiftUnsigned(y, z) over three long
scalars.
Since the function is non-symmetric, all six permutations of the variables are checked.
Represents the invariant x = Division(y, z) over three double
scalars.
Since the function is non-symmetric, all six permutations of the variables are checked.
Represents the invariant x = Maximum(y, z) over three double
scalars.
Since the function is symmetric, only the permutations xyz, yxz, and zxy are checked.
Represents the invariant x = Minimum(y, z) over three double
scalars.
Since the function is symmetric, only the permutations xyz, yxz, and zxy are checked.
Represents the invariant x = Multiply(y, z) over three double
scalars.
Since the function is symmetric, only the permutations xyz, yxz, and zxy are checked.
This is a special implication invariant that guards any invariants that are over variables that
are sometimes missing. For example, if the invariant a.x = 0 is true, the guarded
implication is a != null => a.x = 0.
The Implication invariant class is used internally within Daikon to handle invariants that are only true when certain other conditions are also true (splitting).
Represents an invariant of == between two long scalars. Prints as x == y.
Represents an invariant of >= between two long scalars. Prints as x >= y.
Represents an invariant of > between two long scalars. Prints as x > y.
Represents an invariant of <= between two long scalars. Prints as x <= y.
Represents an invariant of < between two long scalars. Prints as x < y.
Represents an invariant of != between two long scalars. Prints as x != y.
See also the following configuration option:
IsPointer is an invariant that heuristically determines whether an integer represents a pointer (a 32-bit memory address). Since both a 32-bit integer and an address have the same representation, sometimes a a pointer can be mistaken for an integer. When this happens, several scalar invariants are computed for integer variables. Most of them would not make any sense for pointers. Determining whether a 32-bit variable is a pointer can thus spare the computation of many irrelevant invariants.
The basic approach is to discard the invariant if any values that are not valid pointers are encountered. By default values between -100,000 and 100,000 (except 0) are considered to be invalid pointers. This approach has been experimentally confirmed on Windows x86 executables.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.scalar.IsPointer.enabled’.
Represents a Linear invariant between two long scalars x and y, of
the form ax + by + c = 0. The constants a, b and
c are mutually relatively prime, and the constant a is always positive.
Represents a Linear invariant between two double scalars x and y, of
the form ax + by + c = 0. The constants a, b and
c are mutually relatively prime, and the constant a is always positive.
Represents a Linear invariant over three long scalars x,
y, and z, of the form
ax + by + cz + d = 0.
The constants a, b, c, and
d are mutually relatively prime, and the constant
a is always positive.
Represents a Linear invariant over three double scalars x,
y, and z, of the form
ax + by + cz + d = 0.
The constants a, b, c, and
d are mutually relatively prime, and the constant
a is always positive.
Represents the invariant x >= c, where c is a constant and
x is a long scalar.
See also the following configuration options:
Represents the invariant x >= c, where c is a constant and
x is a double scalar.
See also the following configuration options:
Represents long scalars that are always members of a sequence of long values. Prints as
x in y[] where x is a long scalar and y[] is a sequence
of long.
Represents double scalars that are always members of a sequence of double values. Prints as
x in y[] where x is a double scalar and y[] is a sequence
of double.
Represents String scalars that are always members of a sequence of String values. Prints as
x in y[] where x is a String scalar and y[] is a sequence
of String.
Represents the invariant x == r (mod m) where x is a long scalar variable, r is the (constant) remainder, and m is the (constant) modulus.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.scalar.Modulus.enabled’.
Represents sequences of long that contain no duplicate elements. Prints as
x[] contains no duplicates.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.NoDuplicates.enabled’.
Represents sequences of double that contain no duplicate elements. Prints as
x[] contains no duplicates.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.NoDuplicatesFloat.enabled’.
Represents long scalars that are never equal to r (mod m) where all other numbers in the
same range (i.e., all the values that x doesn’t take from min(x) to max(x)) are equal to r (mod m). Prints as x != r (mod m), where r is the
remainder and m is the modulus.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.scalar.NonModulus.enabled’.
Represents long scalars that are non-zero. Prints as x != 0, or as x !=
null for pointer types.
Represents double scalars that are non-zero. Prints as x != 0.
Represents the divides without remainder invariant between two double scalars.
Prints as x % y == 0.
Represents the square invariant between two double scalars.
Prints as x = y**2.
Represents the zero tracks invariant between
two double scalars; that is, when x is zero,
y is also zero.
Prints as x = 0 => y = 0.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoScalar.NumericFloat.ZeroTrack.enabled’.
Represents the BitwiseAnd == 0 invariant between two long scalars; that is, x and
y have no bits in common.
Prints as x & y == 0.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoScalar.NumericInt.BitwiseAndZero.enabled’.
Represents the bitwise complement invariant between two long scalars.
Prints as x = ~y.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoScalar.NumericInt.BitwiseComplement.enabled’.
Represents the bitwise subset invariant between two long scalars; that is, the bits of
y are a subset of the bits of x.
Prints as x = y | x.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoScalar.NumericInt.BitwiseSubset.enabled’.
Represents the divides without remainder invariant between two long scalars.
Prints as x % y == 0.
Represents the ShiftZero invariant between two long scalars; that is, x
right-shifted by y is always zero.
Prints as x >> y = 0.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoScalar.NumericInt.ShiftZero.enabled’.
Represents the square invariant between two long scalars.
Prints as x = y**2.
Represents the zero tracks invariant between
two long scalars; that is, when x is zero,
y is also zero.
Prints as x = 0 => y = 0.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoScalar.NumericInt.ZeroTrack.enabled’.
Represents double variables that take on only a few distinct values. Prints as either
x == c (when there is only one value) or as x one of {c1, c2, c3}
(when there are multiple values).
See also the following configuration option:
Represents double[] variables that take on only a few distinct values. Prints as either
x == c (when there is only one value) or as x one of {c1, c2, c3}
(when there are multiple values).
See also the following configuration option:
Represents long variables that take on only a few distinct values. Prints as either
x == c (when there is only one value) or as x one of {c1, c2, c3}
(when there are multiple values).
May print as x has only one value when x is a hashcode (pointer) – this is
because the numerical value of the hashcode (pointer) is uninteresting.
See also the following configuration options:
Represents long[] variables that take on only a few distinct values. Prints as either
x == c (when there is only one value) or as x one of {c1, c2, c3}
(when there are multiple values).
See also the following configuration options:
Represents String variables that take on only a few distinct values. Prints as either
x == c (when there is only one value) or as x one of {c1, c2, c3}
(when there are multiple values).
See also the following configuration option:
Represents String[] variables that take on only a few distinct values. Prints as either
x == c (when there is only one value) or as x one of {c1, c2, c3}
(when there are multiple values).
See also the following configuration option:
Represents an invariant between corresponding elements of two sequences of double values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] == y[].
Represents an invariant between corresponding elements of two sequences of double values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] >= y[].
Represents an invariant between corresponding elements of two sequences of double values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] > y[].
Represents an invariant between corresponding elements of two sequences of double values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] <= y[].
Represents an invariant between corresponding elements of two sequences of double values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] < y[].
Represents an invariant between corresponding elements of two sequences of long values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] == y[].
Represents an invariant between corresponding elements of two sequences of long values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] >= y[].
Represents an invariant between corresponding elements of two sequences of long values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] > y[].
Represents an invariant between corresponding elements of two sequences of long values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] <= y[].
Represents an invariant between corresponding elements of two sequences of long values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] < y[].
Represents a linear invariant (i.e., y = ax + b) between the corresponding elements
of two sequences of long values. Each (x[i], y[i]) pair is examined. Thus,
x[0] is compared to y[0], x[1] to y[1] and so
forth. Prints as y[] = a * x[] + b.
Represents a linear invariant (i.e., y = ax + b) between the corresponding elements
of two sequences of double values. Each (x[i], y[i]) pair is examined. Thus,
x[0] is compared to y[0], x[1] to y[1] and so
forth. Prints as y[] = a * x[] + b.
Represents the divides without remainder invariant between corresponding elements of two sequences of double.
Prints as x[] % y[] == 0.
Represents the square invariant between corresponding elements of two sequences of double.
Prints as x[] = y[]**2.
Represents the zero tracks invariant between
corresponding elements of two sequences of double; that is, when x[] is zero,
y[] is also zero.
Prints as x[] = 0 => y[] = 0.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.PairwiseNumericFloat.ZeroTrack.enabled’.
Represents the BitwiseAnd == 0 invariant between corresponding elements of two sequences of long; that is, x[] and
y[] have no bits in common.
Prints as x[] & y[] == 0.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.PairwiseNumericInt.BitwiseAndZero.enabled’.
Represents the bitwise complement invariant between corresponding elements of two sequences of long.
Prints as x[] = ~y[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.PairwiseNumericInt.BitwiseComplement.enabled’.
Represents the bitwise subset invariant between corresponding elements of two sequences of long; that is, the bits of
y[] are a subset of the bits of x[].
Prints as x[] = y[] | x[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.PairwiseNumericInt.BitwiseSubset.enabled’.
Represents the divides without remainder invariant between corresponding elements of two sequences of long.
Prints as x[] % y[] == 0.
Represents the ShiftZero invariant between corresponding elements of two sequences of long; that is, x[]
right-shifted by y[] is always zero.
Prints as x[] >> y[] = 0.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.PairwiseNumericInt.ShiftZero.enabled’.
Represents the square invariant between corresponding elements of two sequences of long.
Prints as x[] = y[]**2.
Represents the zero tracks invariant between
corresponding elements of two sequences of long; that is, when x[] is zero,
y[] is also zero.
Prints as x[] = 0 => y[] = 0.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.PairwiseNumericInt.ZeroTrack.enabled’.
Represents the substring invariant between corresponding elements of two sequences of String.
Prints as x[] is a substring of y[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.PairwiseString.SubString.enabled’.
Represents an invariant between corresponding elements of two sequences of String values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] == y[].
Represents an invariant between corresponding elements of two sequences of String values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] >= y[].
Represents an invariant between corresponding elements of two sequences of String values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] > y[].
Represents an invariant between corresponding elements of two sequences of String values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] <= y[].
Represents an invariant between corresponding elements of two sequences of String values. The
length of the sequences must match for the invariant to hold. A comparison is made over each
(x[i], y[i]) pair. Thus, x[0] is compared to y[0],
x[1] to y[1], and so forth. Prints as x[] < y[].
Represents the invariant x > 0 where x is a long scalar. This exists only as an
example for the purposes of the manual. It isn’t actually used (it is replaced by the more
general invariant LowerBound).
Represents a string that contains only printable ascii characters (values 32 through 126 plus 9 (tab).
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.string.PrintableString.enabled’.
Internal invariant representing double scalars that are equal to minus one. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Internal invariant representing double scalars that are equal to one. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Internal invariant representing double scalars that are equal to zero. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Internal invariant representing double scalars that are greater than or equal to 64. Used for non-instantiating suppressions. Will never print since Bound accomplishes the same thing.
Internal invariant representing double scalars that are greater than or equal to 0. Used for non-instantiating suppressions. Will never print since Bound accomplishes the same thing.
Internal invariant representing longs whose values are always 0 or 1. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Internal invariant representing longs whose values are between 0 and 63. Used for non-instantiating suppressions. Will never print since Bound accomplishes the same thing.
Internal invariant representing long scalars that are equal to minus one. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Internal invariant representing long scalars that are equal to one. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Internal invariant representing long scalars that are equal to zero. Used for non-instantiating suppressions. Will never print since OneOf accomplishes the same thing.
Invariant representing longs whose values are always even. Used for non-instantiating
suppressions. Since this is not covered by the Bound or OneOf invariants it is printed. Prints
as x is even.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.scalar.RangeInt.Even.enabled’.
Internal invariant representing long scalars that are greater than or equal to 64. Used for non-instantiating suppressions. Will never print since Bound accomplishes the same thing.
Internal invariant representing long scalars that are greater than or equal to 0. Used for non-instantiating suppressions. Will never print since Bound accomplishes the same thing.
Invariant representing longs whose values are always a power of 2 (exactly one bit is set).
Used for non-instantiating suppressions. Since this is not covered by the Bound or OneOf
invariants it is printed. Prints as x is a power of 2.
Represents two sequences of long where one is in the reverse order of the other. Prints as
x[] is the reverse of y[].
Represents two sequences of double where one is in the reverse order of the other. Prints as
x[] is the reverse of y[].
Represents an invariant between a double scalar and a a sequence of double values. Prints
as x[] elements == y where x is a double sequence and
y is a double scalar.
Represents an invariant between a double scalar and a a sequence of double values. Prints
as x[] elements >= y where x is a double sequence and
y is a double scalar.
Represents an invariant between a double scalar and a a sequence of double values. Prints
as x[] elements > y where x is a double sequence and
y is a double scalar.
Represents an invariant between a double scalar and a a sequence of double values. Prints
as x[] elements <= y where x is a double sequence and
y is a double scalar.
Represents an invariant between a double scalar and a a sequence of double values. Prints
as x[] elements < y where x is a double sequence and
y is a double scalar.
Represents an invariant over sequences of double values between the index of an element of the
sequence and the element itself. Prints as x[i] == i.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.SeqIndexFloatEqual.enabled’.
Represents an invariant over sequences of double values between the index of an element of the
sequence and the element itself. Prints as x[i] >= i.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.SeqIndexFloatGreaterEqual.enabled’.
Represents an invariant over sequences of double values between the index of an element of the
sequence and the element itself. Prints as x[i] > i.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.SeqIndexFloatGreaterThan.enabled’.
Represents an invariant over sequences of double values between the index of an element of the
sequence and the element itself. Prints as x[i] <= i.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.SeqIndexFloatLessEqual.enabled’.
Represents an invariant over sequences of double values between the index of an element of the
sequence and the element itself. Prints as x[i] < i.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.SeqIndexFloatLessThan.enabled’.
Represents an invariant over sequences of double values between the index of an element of the
sequence and the element itself. Prints as x[i] != i.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.SeqIndexFloatNonEqual.enabled’.
Represents an invariant over sequences of long values between the index of an element of the
sequence and the element itself. Prints as x[i] == i.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.SeqIndexIntEqual.enabled’.
Represents an invariant over sequences of long values between the index of an element of the
sequence and the element itself. Prints as x[i] >= i.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.SeqIndexIntGreaterEqual.enabled’.
Represents an invariant over sequences of long values between the index of an element of the
sequence and the element itself. Prints as x[i] > i.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.SeqIndexIntGreaterThan.enabled’.
Represents an invariant over sequences of long values between the index of an element of the
sequence and the element itself. Prints as x[i] <= i.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.SeqIndexIntLessEqual.enabled’.
Represents an invariant over sequences of long values between the index of an element of the
sequence and the element itself. Prints as x[i] < i.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.SeqIndexIntLessThan.enabled’.
Represents an invariant over sequences of long values between the index of an element of the
sequence and the element itself. Prints as x[i] != i.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.unary.sequence.SeqIndexIntNonEqual.enabled’.
Represents an invariant between a long scalar and a a sequence of long values. Prints
as x[] elements == y where x is a long sequence and
y is a long scalar.
Represents an invariant between a long scalar and a a sequence of long values. Prints
as x[] elements >= y where x is a long sequence and
y is a long scalar.
Represents an invariant between a long scalar and a a sequence of long values. Prints
as x[] elements > y where x is a long sequence and
y is a long scalar.
Represents an invariant between a long scalar and a a sequence of long values. Prints
as x[] elements <= y where x is a long sequence and
y is a long scalar.
Represents an invariant between a long scalar and a a sequence of long values. Prints
as x[] elements < y where x is a long sequence and
y is a long scalar.
Represents invariants between two sequences of double values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] == y[] lexically.
If order doesn’t matter for each variable, then the sequences are compared to see if they are
set equivalent. Prints as x[] == y[].
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of double values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] >= y[] lexically.
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of double values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] > y[] lexically.
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of double values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] <= y[] lexically.
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of double values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] < y[] lexically.
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of long values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] == y[] lexically.
If order doesn’t matter for each variable, then the sequences are compared to see if they are
set equivalent. Prints as x[] == y[].
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of long values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] >= y[] lexically.
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of long values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] > y[] lexically.
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of long values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] <= y[] lexically.
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of long values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] < y[] lexically.
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of String values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] == y[] lexically.
If order doesn’t matter for each variable, then the sequences are compared to see if they are
set equivalent. Prints as x[] == y[].
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of String values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] >= y[] lexically.
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of String values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] > y[] lexically.
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of String values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] <= y[] lexically.
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents invariants between two sequences of String values. If order matters for each
variable (which it does by default), then the sequences are compared lexically. Prints as
x[] < y[] lexically.
If the auxiliary information (e.g., order matters) doesn’t match between two variables, then this invariant cannot apply to those variables.
Represents the substring invariant between two String scalars.
Prints as x is a substring of y.
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoString.StdString.SubString.enabled’.
Represents an invariant of == between two String scalars. Prints as x == y.
Represents an invariant of >= between two String scalars. Prints as x >= y.
Represents an invariant of > between two String scalars. Prints as x > y.
Represents an invariant of <= between two String scalars. Prints as x <= y.
Represents an invariant of < between two String scalars. Prints as x < y.
Represents an invariant of != between two String scalars. Prints as x != y.
Represents two sequences of long values where one sequence is a subsequence of the
other. Prints as x[] is a subsequence of y[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.SubSequence.enabled’.
Represents two sequences of double values where one sequence is a subsequence of the
other. Prints as x[] is a subsequence of y[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.SubSequenceFloat.enabled’.
Represents two sequences of long values where one of the sequences is a subset of the other; that
is each element of one sequence appears in the other. Prints as either
x[] is a subset of y[] or as x[] is a superset of y[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.SubSet.enabled’.
Represents two sequences of double values where one of the sequences is a subset of the other; that
is each element of one sequence appears in the other. Prints as either
x[] is a subset of y[] or as x[] is a superset of y[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.SubSetFloat.enabled’.
Represents two sequences of long values where one sequence is a subsequence of the
other. Prints as x[] is a subsequence of y[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.SuperSequence.enabled’.
Represents two sequences of double values where one sequence is a subsequence of the
other. Prints as x[] is a subsequence of y[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.SuperSequenceFloat.enabled’.
Represents two sequences of long values where one of the sequences is a subset of the other; that
is each element of one sequence appears in the other. Prints as either
x[] is a subset of y[] or as x[] is a superset of y[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.SuperSet.enabled’.
Represents two sequences of double values where one of the sequences is a subset of the other; that
is each element of one sequence appears in the other. Prints as either
x[] is a subset of y[] or as x[] is a superset of y[].
This invariant is not enabled by default. See the configuration option ‘daikon.inv.binary.twoSequence.SuperSetFloat.enabled’.
Represents the invariant x <= c, where c is a constant and
x is a long scalar.
See also the following configuration options:
Represents the invariant x <= c, where c is a constant and
x is a double scalar.
See also the following configuration options:
Previous: Invariant list, Up: Daikon output [Contents][Index]
Invariant filters are used to suppress the printing of invariants that are true, but not considered “interesting” — usually because the invariants are considered obvious or redundant in a given context.
The following is a list of the invariant filters that Daikon supports. Each of these filters has a corresponding configuration enable switch; by default, all filters are enabled. See Options to enable/disable filters, for details.
This filter suppresses invariants at procedure exit points that are
uninteresting because they refer to ‘pre-state’ variables derived from
pass-by-value parameters. For example, suppose that param is a
parameter to a
Java method. If param itself is modified, that change won’t be
visible to a caller, so it’s uninteresting to print. If param points
to an object, and that object is changed, that is visible, but
only if param hasn’t changed; otherwise, the invariant would report a
change in some object other than the one that was passed in.
This filter suppresses any invariant that is a logical consequence of other invariants that are printed. This keeps the output from becoming cluttered with redundant facts. Some examples are:
To suppress even more invariants, use the --suppress_redundant command-line option; see Options to control invariant detection.
This filter suppresses comparison invariants in which all of the variables being compared were observed to be constant. In the current version of Daikon, most such invariants are not even created in the first place, because constants are detected on an early pass over the data. However, Daikon will note that all of the invariants that had any particular constant value were also equal to each other: such invariants will be suppressed by this filter.
A controlled invariant is an invariant that is “controlled” — or
implied — by a parent program point in the dataflow hierarchy.
For example, for Java instrumented
code each class is associated with an object program point, which
contain invariants that are found at the entry and exit of all public
methods. So in addition to the usual program points such as
StackAr.StackAr(int):::ENTER and
StackAr.isEmpty():::EXIT48, Daikon outputs invariants for the
artificial program point StackAr:::OBJECT. The invariants for
StackAr:::OBJECT control the invariants for
StackAr.StackAr(int):::ENTER and
StackAr.isEmpty():::EXIT48, because the former imply the latter.
Because of this redundancy, controlled invariants are not displayed by
default. Note that if for some reason, the controlling invariant is not
displayed (for example, because it’s unjustified), then the controlled
invariant will be displayed.
Daikon contains built-in test that remove most redundant (logically implied) invariants from its output; see
Daikon can use the Simplify theorem-prover to eliminate even more implied invariants than Daikon’s built-in tests are able to eliminate. Simplify must be installed in order to take advantage of this filter (see Installing Simplify).
If you don’t also specify the --suppress_redundant command-line option (see Options to control invariant detection) to enable Simplify processing, this filter doesn’t do anything.
For every invariant, Daikon estimates the probability of that invariant happening by chance. If that probability is less than the limit, then the invariant is deemed to be an actual invariant, not just a chance occurrence. Currently the limit is .01. So by default, only invariants with probabilities of less than 1% are shown. See the --conf_limit option (Options to control invariant detection).
This filter is only useful for ESC output.
Next: Front ends and instrumentation, Previous: Daikon output, Up: Top [Contents][Index]
| • Configuration options | ||
| • Conditional invariants | ||
| • Enhancing conditional invariant detection | ||
| • Dynamic abstract type inference (DynComp) | ||
| • Loop invariants |
Next: Conditional invariants, Up: Enhancing Daikon output [Contents][Index]
Many aspects of Daikon’s behavior can be controlled by setting various configuration parameters. These configuration parameters control which invariants are checked and reported, the statistical tests for invariants, which derived variables are created, and more.
There are two ways to set configuration options. You can specify a configuration setting directly on the command line, using the --config_option name=value option (which you may repeat as many times as you want). Or, you can create a configuration file and supplying it to Daikon on the command line using the --config filename option. Daikon applies all the command-line arguments in order. You may wish to use the supplied example configuration file daikon/java/daikon/config/example-settings.txt as an example when creating your own configuration files. (If you did not download Daikon’s sources, you must extract the example from daikon.jar to read it.)
You can also control Daikon’s output via its command-line options (see Running Daikon) and via the command-line options to its front ends — such as DynComp (see DynComp for Java options), Chicory (see Chicory options) or Kvasir (see Kvasir options).
The configuration options are different from the debugging flags --debug and --dbg category (see Daikon debugging options). The debugging flags permit Daikon to produce debugging output, but they do not affect the invariants that Daikon computes.
| • List of configuration options |
Up: Configuration options [Contents][Index]
This is a list of all Daikon configuration options.
The configuration option name contains the
Java class in which it is defined. (In the Daikon source code, the
configuration value is stored in a variable whose name contains a
dkconfig_ prefix, but that should be irrelevant to users.)
To learn more about a specific invariant or derived variable than
appears in this manual, see its source code.
Next: Options to enable/disable specific invariants, Previous: List of configuration options, Up: List of configuration options [Contents][Index]
These configuration options enable or disable filters that suppress printing
of certain invariants. Invariants are filtered if they are redundant.
See Invariant filters, for more information.
Also see configuration option daikon.PrintInvariants.print_all.
Boolean. If true, DerivedParameterFilter is initially turned on. The default value is ‘true’.
Boolean. If true, DotNetStringFilter is initially turned on. See its Javadoc. The default value is ‘false’.
Boolean. If true, ObviousFilter is initially turned on. The default value is ‘true’.
Boolean. If true, OnlyConstantVariablesFilter is initially turned on. The default value is ‘true’.
Boolean. If true, ParentFilter is initially turned on. The default value is ‘true’.
Boolean. If true, ReadonlyPrestateFilter is initially turned on. The default value is ‘true’.
Boolean. If true, SimplifyFilter is initially turned on. The default value is ‘true’.
Boolean. If true, UnjustifiedFilter is initially turned on. The default value is ‘true’.
Boolean. If true, UnmodifiedVariableEqualityFilter is initially turned on. The default value is ‘true’.
Next: Other invariant configuration parameters, Previous: Options to enable/disable filters, Up: List of configuration options [Contents][Index]
These options control whether Daikon looks for specific kinds of invariants. See Invariant list, for more information about the corresponding invariants.
Boolean. True iff Member invariants should be considered. The default value is ‘true’.
Boolean. True iff Member invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqFloatEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqFloatGreaterEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqFloatGreaterThan invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqFloatLessEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqFloatLessThan invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqIntEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqIntGreaterEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqIntGreaterThan invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqIntLessEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqIntLessThan invariants should be considered. The default value is ‘true’.
Boolean. True iff Member invariants should be considered. The default value is ‘true’.
Boolean. True iff FloatEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff FloatGreaterEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff FloatGreaterThan invariants should be considered. The default value is ‘true’.
Boolean. True iff FloatLessEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff FloatLessThan invariants should be considered. The default value is ‘true’.
Boolean. True iff FloatNonEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff IntEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff IntGreaterEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff IntGreaterThan invariants should be considered. The default value is ‘true’.
Boolean. True iff IntLessEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff IntLessThan invariants should be considered. The default value is ‘true’.
Boolean. True iff IntNonEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff LinearBinary invariants should be considered. The default value is ‘true’.
Boolean. True iff LinearBinary invariants should be considered. The default value is ‘true’.
Boolean. True iff divides invariants should be considered. The default value is ‘true’.
Boolean. True iff square invariants should be considered. The default value is ‘true’.
Boolean. True iff zero-track invariants should be considered. The default value is ‘false’.
Boolean. True iff BitwiseAndZero invariants should be considered. The default value is ‘false’.
Boolean. True iff bitwise complement invariants should be considered. The default value is ‘false’.
Boolean. True iff bitwise subset invariants should be considered. The default value is ‘false’.
Boolean. True iff divides invariants should be considered. The default value is ‘true’.
Boolean. True iff ShiftZero invariants should be considered. The default value is ‘false’.
Boolean. True iff square invariants should be considered. The default value is ‘true’.
Boolean. True iff zero-track invariants should be considered. The default value is ‘false’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseLinearBinary invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseLinearBinary invariants should be considered. The default value is ‘true’.
Boolean. True iff divides invariants should be considered. The default value is ‘true’.
Boolean. True iff square invariants should be considered. The default value is ‘true’.
Boolean. True iff zero-track invariants should be considered. The default value is ‘false’.
Boolean. True iff BitwiseAndZero invariants should be considered. The default value is ‘false’.
Boolean. True iff bitwise complement invariants should be considered. The default value is ‘false’.
Boolean. True iff bitwise subset invariants should be considered. The default value is ‘false’.
Boolean. True iff divides invariants should be considered. The default value is ‘true’.
Boolean. True iff ShiftZero invariants should be considered. The default value is ‘false’.
Boolean. True iff square invariants should be considered. The default value is ‘true’.
Boolean. True iff zero-track invariants should be considered. The default value is ‘false’.
Boolean. True iff SubString invariants should be considered. The default value is ‘false’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff PairwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff Reverse invariants should be considered. The default value is ‘true’.
Boolean. True iff Reverse invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqFloatEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqFloatGreaterEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqFloatGreaterThan invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqFloatLessEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqFloatLessThan invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqIntEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqIntGreaterEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqIntGreaterThan invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqIntLessEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqIntLessThan invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqStringEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqStringGreaterEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqStringGreaterThan invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqStringLessEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqSeqStringLessThan invariants should be considered. The default value is ‘true’.
Boolean. True iff SubSequence invariants should be considered. The default value is ‘false’.
Boolean. True iff SubSequence invariants should be considered. The default value is ‘false’.
Boolean. True iff SubSet invariants should be considered. The default value is ‘false’.
Boolean. True iff SubSet invariants should be considered. The default value is ‘false’.
Boolean. True iff SubSequence invariants should be considered. The default value is ‘false’.
Boolean. True iff SubSequence invariants should be considered. The default value is ‘false’.
Boolean. True iff SubSet invariants should be considered. The default value is ‘false’.
Boolean. True iff SubSet invariants should be considered. The default value is ‘false’.
Boolean. True iff SubString invariants should be considered. The default value is ‘false’.
Boolean. True iff StringEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff StringGreaterEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff StringGreaterThan invariants should be considered. The default value is ‘true’.
Boolean. True iff StringLessEqual invariants should be considered. The default value is ‘true’.
Boolean. True iff StringLessThan invariants should be considered. The default value is ‘true’.
Boolean. True iff StringNonEqual invariants should be considered. The default value is ‘true’.
Boolean. True if FunctionBinary invariants should be considered. The default value is ‘false’.
Boolean. True if FunctionBinaryFloat invariants should be considered. The default value is ‘false’.
Boolean. True iff LinearTernary invariants should be considered. The default value is ‘true’.
Boolean. True iff LinearTernary invariants should be considered. The default value is ‘true’.
Boolean. True iff CompleteOneOfScalar invariants should be considered. The default value is ‘false’.
Boolean. True iff IsPointer invariants should be considered. The default value is ‘false’.
Boolean. True iff LowerBound invariants should be considered. The default value is ‘true’.
Boolean. True iff LowerBoundFloat invariants should be considered. The default value is ‘true’.
Boolean. True iff Modulus invariants should be considered. The default value is ‘false’.
Boolean. True iff NonModulus invariants should be considered. The default value is ‘false’.
Boolean. True iff NonZero invariants should be considered. The default value is ‘true’.
Boolean. True iff NonZeroFloat invariants should be considered. The default value is ‘true’.
Boolean. True iff OneOf invariants should be considered. The default value is ‘true’.
Boolean. True iff OneOf invariants should be considered. The default value is ‘true’.
Boolean. True iff Positive invariants should be considered. The default value is ‘true’.
Boolean. True if Even invariants should be considered. The default value is ‘false’.
Boolean. True if PowerOfTwo invariants should be considered. The default value is ‘true’.
Boolean. True iff UpperBound invariants should be considered. The default value is ‘true’.
Boolean. True iff UpperBoundFloat invariants should be considered. The default value is ‘true’.
Boolean. True iff CommonSequence invariants should be considered. The default value is ‘false’.
Boolean. True iff CommonSequence invariants should be considered. The default value is ‘false’.
Boolean. True iff EltLowerBound invariants should be considered. The default value is ‘true’.
Boolean. True iff EltLowerBoundFloat invariants should be considered. The default value is ‘true’.
Boolean. True iff EltNonZero invariants should be considered. The default value is ‘true’.
Boolean. True iff EltNonZero invariants should be considered. The default value is ‘true’.
Boolean. True iff OneOf invariants should be considered. The default value is ‘true’.
Boolean. True iff OneOf invariants should be considered. The default value is ‘true’.
Boolean. True if Even invariants should be considered. The default value is ‘false’.
Boolean. True if PowerOfTwo invariants should be considered. The default value is ‘true’.
Boolean. True iff EltUpperBound invariants should be considered. The default value is ‘true’.
Boolean. True iff EltUpperBoundFloat invariants should be considered. The default value is ‘true’.
Boolean. True iff EltwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff EltwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff EltwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff EltwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff EltwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff EltwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff EltwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff EltwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff EltwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff EltwiseIntComparison invariants should be considered. The default value is ‘true’.
Boolean. True iff NoDuplicates invariants should be considered. The default value is ‘false’.
Boolean. True iff NoDuplicates invariants should be considered. The default value is ‘false’.
Boolean. True iff OneOf invariants should be considered. The default value is ‘true’.
Boolean. True iff OneOf invariants should be considered. The default value is ‘true’.
Boolean. True iff SeqIndexFloatEqual invariants should be considered. The default value is ‘false’.
Boolean. True iff SeqIndexFloatGreaterEqual invariants should be considered. The default value is ‘false’.
Boolean. True iff SeqIndexFloatGreaterThan invariants should be considered. The default value is ‘false’.
Boolean. True iff SeqIndexFloatLessEqual invariants should be considered. The default value is ‘false’.
Boolean. True iff SeqIndexFloatLessThan invariants should be considered. The default value is ‘false’.
Boolean. True iff SeqIndexFloatNonEqual invariants should be considered. The default value is ‘false’.
Boolean. True iff SeqIndexIntEqual invariants should be considered. The default value is ‘false’.
Boolean. True iff SeqIndexIntGreaterEqual invariants should be considered. The default value is ‘false’.
Boolean. True iff SeqIndexIntGreaterThan invariants should be considered. The default value is ‘false’.
Boolean. True iff SeqIndexIntLessEqual invariants should be considered. The default value is ‘false’.
Boolean. True iff SeqIndexIntLessThan invariants should be considered. The default value is ‘false’.
Boolean. True iff SeqIndexIntNonEqual invariants should be considered. The default value is ‘false’.
Boolean. True iff CompleteOneOfString invariants should be considered. The default value is ‘false’.
Boolean. True iff OneOf invariants should be considered. The default value is ‘true’.
Boolean. True iff PrintableString invariants should be considered. The default value is ‘false’.
Boolean. True iff CommonStringSequence invariants should be considered. The default value is ‘false’.
Boolean. True iff OneOf invariants should be considered. The default value is ‘true’.
Boolean. True iff OneOf invariants should be considered. The default value is ‘true’.
Next: Options to enable/disable derived variables, Previous: Options to enable/disable specific invariants, Up: List of configuration options [Contents][Index]
The configuration options listed in this section parameterize the behavior of certain invariants. See Invariant list, for more information about the invariants.
Floating-point number between 0 and 1. Invariants are displayed only if the confidence that the
invariant did not occur by chance is greater than this. (May also be set via the --conf_limit command-line option to Daikon; refer to manual.)
The default value is ‘0.99’.
Floating-point number between 0 and 0.1, representing the maximum relative difference between
two floats for fuzzy comparisons. Larger values will result in floats that are relatively
farther apart being treated as equal. A value of 0 essentially disables fuzzy comparisons.
Specifically, if abs(1 - f1/f2) is less than or equal to this value, then the two
doubles (f1 and f2) will be treated as equal by Daikon.
The default value is ‘1.0E-4’.
A boolean value. If true, Daikon’s Simplify output (printed when the --format simplify
flag is enabled, and used internally by --suppress_redundant) will include new
predicates representing some complex relationships in invariants, such as lexical ordering
among sequences. If false, some complex relationships will appear in the output as complex
quantified formulas, while others will not appear at all. When enabled, Simplify may be able to
make more inferences, allowing --suppress_redundant to suppress more redundant
invariants, but Simplify may also run more slowly.
The default value is ‘false’.
Boolean. True iff IntNonEqual invariants should be considered. The default value is ‘true’.
Regular expression to match against the class name of derived variables. Invariants that contain derived variables that match will be filtered out. If null, nothing will be filtered out. The default value is ‘null’.
Long integer. Together with the corresponding minimal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of LowerBound invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘2’.
Long integer. Together with the corresponding maximal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of LowerBound invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘-1’.
Long integer. Together with the corresponding minimal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of LowerBoundFloat invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘2’.
Long integer. Together with the corresponding maximal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of LowerBoundFloat invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘-1’.
Positive integer. Specifies the maximum set size for this type of invariant (x is one of
size items).
The default value is ‘3’.
Boolean. If true, invariants describing hashcode-typed variables as having any particular value
will have an artificial value substituted for the exact hashhode values. The artificial values
will stay the same from run to run even if the actual hashcode values change (as long as the
OneOf invariants remain the same). If false, hashcodes will be formatted as the application of
a hashcode uninterpreted function to an integer representing the bit pattern of the hashcode.
One might wish to omit the exact values of the hashcodes because they are usually
uninteresting; this is the same reason they print in the native Daikon format, for instance, as
var has only one value rather than var == 150924732.
The default value is ‘false’.
Positive integer. Specifies the maximum set size for this type of invariant (x is one of
size items).
The default value is ‘3’.
Long integer. Together with the corresponding minimal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of UpperBound invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘2’.
Long integer. Together with the corresponding maximal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of UpperBound invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘-1’.
Long integer. Together with the corresponding minimal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of UpperBoundFloat invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘2’.
Long integer. Together with the corresponding maximal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of UpperBoundFloat invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘-1’.
Boolean. Set to true to consider common sequences over hashcodes (pointers). The default value is ‘false’.
Boolean. Set to true to consider common sequences over hashcodes (pointers). The default value is ‘false’.
Long integer. Together with the corresponding minimal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of EltLowerBound invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘2’.
Long integer. Together with the corresponding maximal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of EltLowerBound invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘-1’.
Long integer. Together with the corresponding minimal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of EltLowerBoundFloat invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘2’.
Long integer. Together with the corresponding maximal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of EltLowerBoundFloat invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘-1’.
Boolean. If true, invariants describing hashcode-typed variables as having any particular value
will have an artificial value substituted for the exact hashhode values. The artificial values
will stay the same from run to run even if the actual hashcode values change (as long as the
OneOf invariants remain the same). If false, hashcodes will be formatted as the application of
a hashcode uninterpreted function to an integer representing the bit pattern of the hashcode.
One might wish to omit the exact values of the hashcodes because they are usually
uninteresting; this is the same reason they print in the native Daikon format, for instance, as
var has only one value rather than var == 150924732.
The default value is ‘false’.
Positive integer. Specifies the maximum set size for this type of invariant (x is one of
size items).
The default value is ‘3’.
Positive integer. Specifies the maximum set size for this type of invariant (x is one of
size items).
The default value is ‘3’.
Long integer. Together with the corresponding minimal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of EltUpperBound invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘2’.
Long integer. Together with the corresponding maximal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of EltUpperBound invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘-1’.
Long integer. Together with the corresponding minimal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of EltUpperBoundFloat invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘2’.
Long integer. Together with the corresponding maximal_interesting parameter,
specifies the range of the computed constant that is “interesting” — the range that should
be reported. For instance, setting minimal_interesting to -1 and
maximal_interesting to 2 would only permit output of EltUpperBoundFloat invariants whose
cutoff was one of (-1,0,1,2).
The default value is ‘-1’.
Positive integer. Specifies the maximum set size for this type of invariant (x is one of
size items).
The default value is ‘3’.
Boolean. If true, invariants describing hashcode-typed variables as having any particular value
will have an artificial value substituted for the exact hashhode values. The artificial values
will stay the same from run to run even if the actual hashcode values change (as long as the
OneOf invariants remain the same). If false, hashcodes will be formatted as the application of
a hashcode uninterpreted function to an integer representing the bit pattern of the hashcode.
One might wish to omit the exact values of the hashcodes because they are usually
uninteresting; this is the same reason they print in the native Daikon format, for instance, as
var has only one value rather than var == 150924732.
The default value is ‘false’.
Positive integer. Specifies the maximum set size for this type of invariant (x is one of
size items).
The default value is ‘3’.
Boolean. Set to true to disable all SeqIndex invariants (SeqIndexIntEqual, SeqIndexFloatLessThan, etc). This overrides the settings of the individual SeqIndex enable configuration options. To disable only some options, the options must be disabled individually. The default value is ‘false’.
Positive integer. Specifies the maximum set size for this type of invariant (x is one of
size items).
The default value is ‘3’.
Positive integer. Specifies the maximum set size for this type of invariant (x is one of
size items).
The default value is ‘3’.
Positive integer. Specifies the maximum set size for this type of invariant (x is one of
size items).
The default value is ‘2’.
Next: Simplify interface configuration options, Previous: Other invariant configuration parameters, Up: List of configuration options [Contents][Index]
These options control whether Daikon looks for invariants involving certain forms of derived variables. Also see Variable names.
Boolean. If true, Daikon will not create any derived variables. Derived variables, which are
combinations of variables that appeared in the program, like array[index] if array and index appeared, can increase the number of properties Daikon finds,
especially over sequences. However, derived variables increase Daikon’s time and memory usage,
sometimes dramatically. If false, individual kinds of derived variables can be enabled or
disabled individually using configuration options under daikon.derive.
The default value is ‘false’.
Boolean. True iff SequenceFloatIntersection derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceFloatSubscript derived variables should be generated. The default value is ‘true’.
Boolean. True iff SequenceFloatSubsequence derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceFloatUnion derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceScalarIntersection derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceScalarSubscript derived variables should be generated. The default value is ‘true’.
Boolean. True iff SequenceScalarSubsequence derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceScalarUnion derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceStringIntersection derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceStringSubscript derived variables should be generated. The default value is ‘true’.
Boolean. True iff SequenceStringSubsequence derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceStringUnion derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequencesConcat derived variables should be created. The default value is ‘false’.
Boolean. True iff SequencesJoin derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequencesJoin derived variables should be generated. The default value is ‘false’.
Boolean. True if Daikon should only generate derivations on boolean predicates. The default value is ‘true’.
Boolean. True iff SequencesPredicate derived variables should be generated. The default value is ‘false’.
Boolean. True if Daikon should only generate derivations on fields of the same data structure. The default value is ‘true’.
Boolean. True if Daikon should only generate derivations on boolean predicates. The default value is ‘true’.
Boolean. True iff SequencesPredicate derived variables should be generated. The default value is ‘false’.
Boolean. True if Daikon should only generate derivations on fields of the same data structure. The default value is ‘true’.
Boolean. True iff SequenceFloatArbitrarySubsequence derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceScalarArbitrarySubsequence derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceStringArbitrarySubsequence derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceInitial derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceInitial derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceLength derived variables should be generated. The default value is ‘true’.
Boolean. True iff SequencesMax derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceMin derived variables should be generated. The default value is ‘false’.
Boolean. True iff SequenceSum derived variables should be generated. The default value is ‘false’.
Boolean. True iff StringLength derived variables should be generated. The default value is ‘false’.
Next: Splitter options, Previous: Options to enable/disable derived variables, Up: List of configuration options [Contents][Index]
The configuration options in this section are used to customize the interface to the Simplify theorem prover. See the description of the --suppress_redundant command-line option in Options to control invariant detection.
Boolean. Controls Daikon’s response when inconsistent invariants are discovered while running Simplify. If true, Daikon will print an error message to the standard error stream listing the contradictory invariants. This is mainly intended for debugging Daikon itself, but can sometimes be helpful in tracing down other problems. For more information, see the section on troubleshooting contradictory invariants in the Daikon manual. The default value is ‘false’.
Boolean. Controls Daikon’s response when inconsistent invariants are discovered while running Simplify. If false, Daikon will give up on using Simplify for that program point. If true, Daikon will try to find a small subset of the invariants that cause the contradiction and avoid them, to allow processing to continue. For more information, see the section on troubleshooting contradictory invariants in the Daikon manual. The default value is ‘true’.
Boolean. If true, ask Simplify to check a simple proposition after each assumption is pushed, providing an opportunity to wait for output from Simplify and potentially receive error messages about the assumption. When false, long sequences of assumptions may be pushed in a row, so that by the time an error message arrives, it’s not clear which input caused the error. Of course, Daikon’s input to Simplify isn’t supposed to cause errors, so this option should only be needed for debugging. The default value is ‘false’.
A non-negative integer, representing the largest number of iterations for which Simplify should
be allowed to run on any single conjecture before giving up. Larger values may cause Simplify
to run longer, but will increase the number of invariants that can be recognized as redundant.
The default value is small enough to keep Simplify from running for more than a few seconds on
any one conjecture, allowing it to verify most simple facts without getting bogged down in long
searches. A value of 0 means not to bound the number of iterations at all, though see also the
simplify_timeout parameter..
A non-negative integer, representing the longest time period (in seconds) Simplify should be
allowed to run on any single conjecture before giving up. Larger values may cause Simplify to
run longer, but will increase the number of invariants that can be recognized as redundant.
Roughly speaking, the time spent in Simplify will be bounded by this value, times the number of
invariants generated, though it can be much less. A value of 0 means to not bound Simplify at
all by time, though also see the option simplify_max_iterations. Beware that using this
option might make Daikon’s output depend on the speed of the machine it’s run on.
The default value is ‘0’.
Boolean. If true, the input to the Simplify theorem prover will also be directed to a file
named simplifyN.in (where N is a number starting from 0) in the current directory. Simplify’s
operation can then be reproduced with a command like Simplify -nosc <simplify0.in. This
is intended primarily for debugging when Simplify fails.
The default value is ‘false’.
Positive values mean to print extra indications as each candidate invariant is passed to
Simplify during the --suppress_redundant check. If the value is 1 or higher, a hyphen
will be printed when each invariant is passed to Simplify, and then replaced by a T if
the invariant was redundant, F if it was not found to be, and ? if Simplify
gave up because of a time limit. If the value is 2 or higher, a < or > will
also be printed for each invariant that is pushed onto or popped from from Simplify’s
assumption stack. This option is mainly intended for debugging purposes, but can also provide
something to watch when Simplify takes a long time.
The default value is ‘0’.
Next: Debugging options, Previous: Simplify interface configuration options, Up: List of configuration options [Contents][Index]
The configuration options in this section are used to customize the behavior of splitters, which yield conditional invariants and implications (see Conditional invariants).
Enumeration (integer). Specifies the granularity to use for callsite splitter processing. (That is, for creating invariants for a method that are dependent on where the method was called from.) 0 is line-level granularity; 1 is method-level granularity; 2 is class-level granularity. The default value is ‘1’.
Boolean. If true, the built-in splitting rules are disabled. The built-in rules look for implications based on boolean return values and also when there are exactly two exit points from a method. The default value is ‘false’.
Integer. A value of zero indicates that DummyInvariant objects should not be created. A value of one indicates that dummy invariants should be created only when no suitable condition was found in the regular output. A value of two indicates that dummy invariants should be created for each splitting condition. The default value is ‘0’.
Split bi-implications ("a <==> b") into two separate implications ("a ==> b"
and "b ==> a").
The default value is ‘false’.
When true, compilation errors during splitter file generation will not be reported to the user. The default value is ‘true’.
Positive integer. Specifies the Splitter compilation timeout, in seconds, after which the compilation process is terminated and retried, on the assumption that it has hung. The default value is ‘20’.
String. Specifies which Java compiler is used to compile Splitters. This can be the full path name or whatever is used on the command line. Uses the current classpath. The default value is ‘javac -nowarn -source 8 -target 8 -classpath /homes/gws/markro/jdk1.8.0_401/lib/tools.jar:/homes/gws/markro/jdk1.8.0_401/classes’.
Boolean. If true, the temporary Splitter files are deleted on exit. Set it to "false" if you are debugging splitters. The default value is ‘true’.
Boolean. Enables indiscriminate splitting (see Daikon manual, Indiscriminate splitting, for an explanation of this technique). The default value is ‘true’.
Next: Quantity of output, Previous: Splitter options, Up: List of configuration options [Contents][Index]
The configuration options in this section are used to cause extra output that is useful for debugging. Also see section "Daikon debugging options" (see Daikon debugging options).
When true, perform detailed internal checking. These are essentially additional, possibly costly assert statements. The default value is ‘false’.
Returns true if detailed info (such as from add_modified) is printed.
The default value is ‘false’.
Returns true if traceback information is printed for each call to log. The default value is ‘false’.
If true, show stack traces for errors such as file format errors. The default value is ‘false’.
Next: General configuration options, Previous: Debugging options, Up: List of configuration options [Contents][Index]
The configuration options in this section make Daikon print more or less output. They do not affect which invariants Daikon computes, only how it outputs them. Also see the following section.
If "always", then invariants are always guarded. If "never", then invariants are never guarded. If "missing", then invariants are guarded only for variables that were missing ("can be missing") in the dtrace (the observed executions). If "default", then use "missing" mode for Java output and "never" mode otherwise.
Guarding means adding predicates that ensure that variables can be dereferenced. For
instance, if a can be null — that is, if a.b can be nonsensical — then the
guarded version of
a.b == 5
is
(a != null) -> (a.b == 5)
.
(To do: Some configuration option (maybe this one) should add guards for other reasons that
lead to nonsensical values (see Variable names).)
The default value is ‘default’.
Boolean. Controls whether conditional program points are displayed. The default value is ‘true’.
Boolean. Controls whether or not the total samples read and processed are printed at the end of processing. The default value is ‘false’.
The amount of time to wait between updates of the progress display, measured in milliseconds. A value of -1 means do not print the progress display at all. The default value is ‘1000’.
The number of columns of progress information to display. In many Unix shells, this can be set
to an appropriate value by --config_option
daikon.Daikon.progress_display_width=$COLUMNS.
The default value is ‘80’.
Boolean. Controls whether or not processing information is printed out. Setting this variable
to true also automatically sets progress_delay to -1.
The default value is ‘false’.
Boolean. When false, don’t count the number of lines in the dtrace file before reading. This will disable the percentage progress printout. The default value is ‘true’.
Long integer. If non-zero, this value will be used as the number of lines in (each) dtrace file input for the purposes of the progress display, and the counting of the lines in the file will be suppressed. The default value is ‘0’.
Boolean. When true, don’t print a warning about unmatched procedure entries, which are ignored
by Daikon (unless the --nohierarchy command-line argument is provided).
The default value is ‘false’.
Boolean. If true, prints the unmatched procedure entries verbosely. The default value is ‘false’.
If true, print all invariants without any filtering. The default value is ‘false’.
Print invariant classname with invariants in output of format() method. Normally used
only for debugging output rather than ordinary printing of invariants. This is especially
useful when two different invariants have the same printed representation.
The default value is ‘false’.
If true, print the total number of true invariants. This includes invariants that are redundant and would normally not be printed or even created due to optimizations. The default value is ‘false’.
Previous: Quantity of output, Up: List of configuration options [Contents][Index]
This section lists miscellaneous configuration options for Daikon.
Boolean. Just print the total number of possible invariants and exit. The default value is ‘false’.
Integer. Percentage of program points to process. All program points are sorted by name, and
all samples for the first ppt_perc program points are processed. A percentage of 100
matches all program points.
The default value is ‘100’.
Boolean. Controls whether the Daikon optimizations (equality sets, suppressions) are undone at the end to create a more complete set of invariants. Output does not include conditional program points, implications, reflexive and partially reflexive invariants. The default value is ‘false’.
Boolean. Controls which invariants are created for variables that are constant for the entire run. If true, create only OneOf invariants. If false, create all possible invariants.
Note that setting this to true only fails to create invariants between constants. Invariants between constants and non-constants are created regardless.
A problem occurs with merging when this is turned on. If a var_info is constant at one child slice, but not constant at the other child slice, interesting invariants may not be merged because they won’t exist on the slice with the constant. This is thus currently defaulted to false. The default value is ‘false’.
If true, use the dynamic constants optimization. This optimization doesn’t instantiate invariants over constant variables (i.e., those that have only seen one value). When the variable receives a second value, invariants are instantiated and are given the sample representing the previous constant value. The default value is ‘true’.
Boolean. When false, set modbits to 1 iff the printed representation has changed. When true, set modbits to 1 if the printed representation has changed; leave other modbits as is. The default value is ‘true’.
Boolean. When true, suppress exceptions related to file reading. This permits Daikon to continue even if there is a malformed trace file. Use this with care: in general, it is better to fix the problem that caused a bad trace file, rather than to suppress the exception. The default value is ‘false’.
When true, just ignore exit ppts that don’t have a matching enter ppt rather than exiting with an error. Unmatched exits can occur if only a portion of a dtrace file is processed. The default value is ‘false’.
Integer. Maximum number of lines to read from the dtrace file. If 0, reads the entire file. The default value is ‘0’.
Boolean. When true, only read the samples, but don’t process them. Used to gather timing information. The default value is ‘false’.
If true, modified all ppt names to remove duplicate routine names within the ppt name. This is used when a stack trace (of active methods) is used as the ppt name. The routine names must be separated by vertical bars (|). The default value is ‘false’.
Boolean. Controls whether the object-user relation is created in the variable hierarchy. The default value is ‘false’.
If true, create one equality set for each variable. This has the effect of turning the equality optimization off, without actually removing the sets themselves (which are presumed to exist in many parts of the code). The default value is ‘false’.
Boolean. If true, create implications for all pairwise combinations of conditions, and all pairwise combinations of exit points. If false, create implications for only the first two conditions, and create implications only if there are exactly two exit points. The default value is ‘false’.
Remove invariants at lower program points when a matching invariant is created at a higher program point. For experimental purposes only. The default value is ‘false’.
In the new decl format, print array names as ’a[]’ as opposed to ’a[..]’ This creates names that are more compatible with the old output. This option has no effect in the old decl format. The default value is ‘true’.
If false, don’t print entry method program points for methods that override or implement another method (i.e., entry program points that have a parent that is a method). Microsoft Code Contracts does not allow contracts on such methods. The default value is ‘true’.
If true, remove as many variables as possible that need to be indicated as ’post’. Post variables occur when the subscript for a derived variable with an orig sequence is not orig. For example: orig(a[post(i)]) An equivalent expression involving only orig variables is substituted for the post variable when one exists. The default value is ‘false’.
This option must be given with "–format Java" option.
Instead of outputting prestate expressions as "\old(E)" within an invariant, output a variable name (e.g. ‘v1’). At the end of each program point, output the list of variable-to-expression mappings. For example: with this option set to false, a program point might print like this:
foo.bar.Bar(int):::EXIT \old(capacity) == sizeof(this.theArray)
With the option set to true, it would print like this:
foo.bar.Bar(int):::EXIT v0 == sizeof(this.theArray) prestate assignment: v0=capacity
The default value is ‘true’.
This enables a different way of treating static constant variables. They are not created into invariants into slices. Instead, they are examined during print time. If a unary invariant contains a value which matches the value of a static constant variable, the value will be replaced by the name of the variable, "if it makes sense". For example, if there is a static constant variable a = 1. And if there exists an invariant x <= 1, x <= a would be the result printed. The default value is ‘false’.
If true, treat 32 bit values whose high bit is on, as a negative number (rather than as a 32 bit unsigned). The default value is ‘false’.
If true, the treat static constants (such as MapQuick.GeoPoint.FACTOR) as fields within an object rather than as a single name. Not correct, but used to obtain compatibility with VarInfoName. The default value is ‘true’.
If true, then variables are only considered comparable if they are declared with the same type. For example, java.util.List is not comparable to java.util.ArrayList and float is not comparable to double. This may miss valid invariants, but significant time can be saved and many variables with different declared types are not comparable (e.g., java.util.Date and java.util.ArrayList). The default value is ‘true’.
When true, apply orig directly to variables, do not apply orig to derived variables. For example, create ’size(orig(a[]))’ rather than ’orig(size(a[]))’. The default value is ‘false’.
Enable experimental techniques on static constants. The default value is ‘false’.
Boolean. If true, enable non-instantiating suppressions. The default value is ‘true’.
Int. Less and equal to this number means use the falsified method in the hybrid method of processing falsified invariants, while greater than this number means use the antecedent method. Empirical data shows that number should not be more than 10000. The default value is ‘2500’.
Boolean. If true, skip variables of file rep type hashcode when creating invariants
over constants in the antecedent method.
The default value is ‘true’.
Specifies the algorithm that NIS uses to process suppressions. Possible selections are ’HYBRID’, ’ANTECEDENT’, and ’FALSIFIED’. The default is the hybrid algorithm which uses the falsified algorithm when only a small number of suppressions need to be processed and the antecedent algorithm when a large number of suppressions are processed. The default value is ‘HYBRID’.
Boolean. If true, use the specific list of suppressor related invariant prototypes when creating constant invariants in the antecedent method. The default value is ‘true’.
Next: Enhancing conditional invariant detection, Previous: Configuration options, Up: Enhancing Daikon output [Contents][Index]
Conditional invariants are invariants that are true only part of the time. For instance, consider the absolute value procedure. Its postcondition is
if arg < 0 then return == -arg else return == arg
The invariant return == -arg is a conditional invariant because
it depends on the predicate arg < 0 being true. An
implication is a compound invariant that includes both the
predicate and the conditional invariant (also called the consequent);
an example of an implication is arg < 0 ==> return == -arg.
Another type of implication is a context-sensitive invariant — a
fact about method A that is true only when A is called by method B, but
not true in general about A.
You can use the configuration option
daikon.split.ContextSplitterFactory.granularity to control creation
of context-sensitive invariants.
Alternately, you can use implications to construct
context-sensitive invariants: set a variable that depends on the call
site, then compute an implication whose predicate tests that variable.
For an example, see the paper Selecting, refining, and evaluating
predicates for program analysis
(http://plse.cs.washington.edu/daikon/pubs/predicates-tr914-abstract.html).
Daikon must be supplied with the predicate for an implication. Daikon has
certain built-in predicates that it uses for finding conditional invariants;
examples are which return statement was executed in a procedure and whether a
boolean procedure returns true or false. Additionally, Daikon can read
predicates from a file called a splitter info (.spinfo) file and find
implications based on those predicates. The splitter info file can be produced
automatically, such as by static analysis of the program using the CreateSpinfo
and CreateSpinfoC programs (see Static analysis for splitters)
or by cluster analysis of the
traced values in the data trace file. Details of these techniques and usage
guides can be found in Enhancing conditional invariant detection. Users
can also create splitter info files themselves or can augment
automatically-created ones.
To detect conditional invariants and implications:
java -cp ${DAIKONDIR}/daikon.jar daikon.Daikon Foo.decls Foo.spinfo Foo.dtrace
The term splitter comes from Daikon’s technique for detecting implications and conditional invariants. For each predicate, Daikon creates two conditional program points — one for program executions that satisfy the condition and one for those that don’t — and splits the data trace into two parts. Invariant detection is then performed on the conditional program points (that is, the parts of the data trace) separately and any invariants detected are reported as conditional invariants (as implications).
To be precise, we say that an invariant holds exclusively if it is discovered on one side of a split, and its negation is discovered on the opposite side. Daikon creates conditional invariants whose predicates are invariants that hold exclusively on one side of a split, and whose consequents are invariants that hold on that side of the split but not on the unsplit program point. If Daikon finds multiple exclusive conditions, it will create biconditional (“if and only if”) invariants between the equivalent conditions. Within the context of the program, each of the exclusive conditions is equivalent to the splitting condition. In particular, if both the splitting condition and its negation are within the grammar of invariants that Daikon detects, the splitting condition may appear as the predicate of the generated conditional invariants. On the other hand, if other equivalent conditions are found, or if the splitting condition is not expressible in Daikon’s grammar, it might not appear in the generated implications.
In some cases, the default policy of selecting predicates from Daikon’s output may be insufficient. For instance, Daikon might not detect any invariant equivalent to the splitting condition, if the splitting condition is sufficiently complex or application-specific. In such situations, Daikon can also use the splitting condition itself, as what is called a dummy invariant. To use dummy invariants, set the configuration option daikon.split.PptSplitter.dummy_invariant_level to a non-zero value (see List of configuration options).
| • Splitter info file format | ||
| • Indiscriminate splitting | ||
| • Example splitter info file |
Next: Indiscriminate splitting, Up: Conditional invariants [Contents][Index]
A splitter info file contains the conditions that Daikon should use to create conditional invariants. Each section in the .spinfo file consists of a sequence of non-blank lines; sections are separated by blank lines. There are two types of sections: program point sections and replacement sections. See Example splitter info file, for an example splitter info file.
| • Program point sections | ||
| • Replacement sections |
Next: Replacement sections, Up: Splitter info file format [Contents][Index]
Program point sections have a line specifying a program point name followed by lines specifying the condition(s) associated with that program point, each condition on its own line. Additional information about a condition may be specified on indented lines. For example, a typical entry is
PPT_NAME pptname
condition1
condition2
DAIKON_FORMAT string
ESC_FORMAT string
condition3
...
pptname can be any string that matches a part of the desired
program point name as printed in the .decls file. In finding matching
program points, Daikon uses the first program point that matches
pptname. Caution is necessary when dealing with method names
that are prefixes of other method names. For instance, if the class
List has methods add and addAll, specifying
‘PPT_NAME List.add’ might select either method, depending on
which was encountered first. Instead writing ‘PPT_NAME
List.add(’ will match only the add method.
Each condition is a Java expression of boolean type. All variables that appear in the condition must also appear in the declaration of the program point in the .decls file. (In other words, all the variables must be in scope at the program point(s) where the Splitter is intended to operate.) The automatically generated Splitter source code fails to compile (but Daikon proceeds without it) if a variable name in a condition is not found at the matching program point.
An indented lines beginning with ‘DAIKON_FORMAT’, ‘JAVA_FORMAT’, ‘ESC_FORMAT’, or ‘SIMPLIFY_FORMAT’ specifies how to print the condition. These are optional; for any Daikon output format that is omitted, the Java condition itself is used. The alternate printed representation is used when the splitting condition is used as a dummy invariant; see configuration option daikon.split.PptSplitter.dummy_invariant_level.
Previous: Program point sections, Up: Splitter info file format [Contents][Index]
Ordinarily, a splitting condition may not invoke user-defined methods, because when Daikon reads data trace files, it does not have access to the program source. A replace section of the splitter info file can specify the bodies of methods, permitting conditions to invoke those methods. The format is as follows:
REPLACE procedure1 replacement1 procedure2 replacement2 ...
where replacementi is a Java expression for the body of procedurei. In each condition, Daikon replaces procedure calls by their replacements. A replace section may appear anywhere in the splitter info file.
Next: Example splitter info file, Previous: Splitter info file format, Up: Conditional invariants [Contents][Index]
Each condition in an .spinfo is associated with a program point. The condition can be used at only that program point by placing the following line in a file that is passed to Daikon via the --config flag (see Daikon configuration options):
daikon.split.SplitterList.all_splitters = false
The default, called indiscriminate splitting, is to use every condition at every program point, regardless of where in the .spinfo file the condition appeared.
The advantage of indiscriminate splitting is that a condition that is useful at one program point may also be useful at another — if the same variables are in scope or other variables of the same name are in scope. The disadvantage of indiscriminate splitting is that it slows Daikon down.
Daikon uses a condition only where it can be used. For example, the
condition myArray.length == x is applicable only at program points
that have variables named myArray and x. To see
warnings about places a splitting condition cannot be used (reported as
failure to compile splitters at those locations), place the following line
in a file that is passed to Daikon via the --config flag
(see Daikon configuration options):
daikon.split.SplitterList.all_splitters_errors = true
Previous: Indiscriminate splitting, Up: Conditional invariants [Contents][Index]
Below is an implementation of a simple Queue for positive integers and
a corresponding .spinfo file. The splitter info file is like
the one that CreateSpinfo would create for that class, but
also demonstrates some other features.
| • Example class | ||
| • Resulting .spinfo file |
Next: Resulting .spinfo file, Up: Example splitter info file [Contents][Index]
class simpleStack {
private int[] myArray;
private int currentSize;
public simpleStack(int capacity) {
myArray = new int[capacity];
currentSize = 0;
}
/** Adds an element to the back of the stack, if the stack is
* not full.
* Returns true if this succeeds, false otherwise. */
public String push(int x) {
if ( !isFull() && x >= 0) {
myArray[currentSize] = x;
currentSize++;
return true;
} else {
return false;
}
}
/** Returns the most recently inserted stack element.
* Returns -1 if the stack is empty. */
public int pop() {
if ( !isEmpty() ) {
currentSize--;
return myArray[currentSize];
} else {
return -1;
}
}
/** Returns true if the stack is empty, false otherwise. */
private boolean isEmpty() {
return (currentSize == 0);
}
/** Returns true if the stack is full, false otherwise. */
private boolean isFull() {
return (currentSize == myArray.length);
}
}
Previous: Example class, Up: Example splitter info file [Contents][Index]
REPLACE
isFull()
currentSize == myArray.length
isEmpty()
currentSize == 0
PPT_NAME simpleStack.push
!isFull() && x >= 0
DAIKON_FORMAT !isFull() and x >= 0
SIMPLIFY_FORMAT (AND (NOT (isFull this)) (>= x 0))
PPT_NAME simpleStack.pop
!isEmpty()
PPT_NAME simpleStack.isFull
currentSize == myArray.length - 1
PPT_NAME simpleStack.isEmpty
currentSize == 0
Next: Dynamic abstract type inference (DynComp), Previous: Conditional invariants, Up: Enhancing Daikon output [Contents][Index]
The built-in mechanisms (see Conditional invariants) have limitations in the invariants they can find. By supplying splitting conditions to Daikon via a splitter info file, the user can infer more conditional invariants. To ease this task, there are methods to automatically create splitter info files for use by Daikon.
| • Static analysis for splitters | ||
| • Cluster analysis for splitters | ||
| • Random selection for splitters |
Next: Cluster analysis for splitters, Up: Enhancing conditional invariant detection [Contents][Index]
In static analysis, all boolean statements in the program source are extracted and used as splitting conditions. The assumption is that conditions that are explicitly tested in the program are likely to affect the program’s behavior and could lead to useful conditional invariants. The simple heuristic of using these conditional statements as predicates for conditional invariant detection is often quite effective.
| • Static analysis of Java for splitters | ||
| • Static analysis of C for splitters |
The CreateSpinfo program takes Java source code as input and creates a
splitter info file for each Java file; for instance,
java -cp ${DAIKONDIR}/daikon.jar daikon.tools.jtb.CreateSpinfo Foo.java Bar.java
creates the splitter info files Foo.spinfo and
Bar.spinfo.
Given an -o filename argument, CreateSpinfo puts all the
splitters in the specified file instead.
The resulting splitter info file(s) contains each
boolean expression that appears in the source code.
If you get an error such as
jtb.ParseException: Encountered ";" at line 253, column 8. Was expecting one of: "abstract" ...
then you may have encountered a bug in the JTB library on which
CreateSpinfo is built. It does not permit empty declarations in a
class body. Remove the extra semicolon in your Java file (at the
indicated position) and re-rerun CreateSpinfo.
Previous: Static analysis of Java for splitters, Up: Static analysis for splitters [Contents][Index]
The CreateSpinfoC program performs the same function for
C source code as CreateSpinfoC does for Java.
CreateSpinfoC can only be run on postprocessed source
files—that is, source files contain no CPP commands. CPP commands
are lines starting with ‘#’, such as ‘#include’. To
expand CPP commands into legal C, run either cpp -P or
gcc -P -E. For instance, here is how you could use CreateSpinfoC:
cpp -P foo.c foo.c-expanded
cpp -P bar.c bar.c-expanded
java -cp ${DAIKONDIR}/daikon.jar daikon.tools.jtb.CreateSpinfoC \
foo.c-expanded bar.c-expanded
WARNING: The names produced by CreateSpinfoC sometimes differ
from the names produced by Kvasir. For example, suppose you have a C
file that contains a function ‘foo’. Then CreateSpinfoC
may create a .spinfo file that mentions a program point named
‘std.foo’, whereas Kvasir creates a .dtrace file that
mentions a program point named ‘..foo’. Such a mismatch will cause
Daikon to produce no conditional invariants for the given program point.
This is a bug that needs to be fixed! (Patches are welcome.) In the
meanwhile, you can edit the generated .spinfo file to conform to the
.dtrace file’s naming conventions.
If you get an error such as
... Lexical error at line 5, column 1. Encountered: "#" (35), after : ""
then you forgot to run CPP before running CreateSpinfoC.
If you get an error such as
CreateSpinfoC encountered errors during parse.
Encountered "__extension__ typedef struct { ...
then your program uses non-standard C syntax. The ‘__extension__’
keyword is supported only by the gcc compiler, and isn’t handled by
the CreateSpinfoC program. You could extend the CreateSpinfoC program
to handle non-standard gcc extensions, or you could remove non-standard
gcc extensions from your program. The extensions might also result from
standard libraries rather than your own program — removing a
directives such as ‘#include <stdio.h>’ when preprocessing may also
resolve the problem.
Next: Random selection for splitters, Previous: Static analysis for splitters, Up: Enhancing conditional invariant detection [Contents][Index]
Cluster analysis is a statistical method that finds groups or clusters in data. The clusters may indicate conditional properties in the program. The cluster analysis mechanism finds clusters in the data trace file, infers invariants over any clusters that it finds, and writes these invariants into a splitter info file. Then, you supply the splitter info file to Daikon in order to infer conditional invariants.
To find splitting conditions using cluster analysis, run the
runcluster.pl program (found in the ${DAIKONDIR}/scripts
directory) in the following way:
runcluster.pl [options] dtrace_file ... decls_files ...
The options are:
ALG specifies a clustering algorithm. Current options are ‘km’ (for kmeans), ‘hierarchical’, and ‘xm’ (for xmeans). The default is ‘xm’.
The number of clusters to use (for algorithms which require this input, which is everything except xmeans). The default is 4.
Don’t delete the temporary files created by the clustering process. This is a debugging flag.
The runcluster.pl script currently supports three clustering
programs. They are implementations of the kmeans algorithm,
hierarchical clustering, and the xmeans algorithm (kmeans algorithm
with efficient discovery of the number of clusters). The kmeans and
hierarchical clustering tools are provided in the Daikon
distribution. The xmeans code and executable are publicly available at
http://www.cs.cmu.edu/~dpelleg/kmeans.html (fill in the license
form and mail it in).
Previous: Cluster analysis for splitters, Up: Enhancing conditional invariant detection [Contents][Index]
Random selection can create representative samples of a data set with
the added benefit of finding conditional properties and eliminating
outliers. Given trace data, the TraceSelect tool creates several
small subsets of the data by randomly selecting parts of the original
trace file. Any invariant that is discovered in the smaller samples but
not found over the entire data is a conditional invariant.
To find splitting conditions using random selection, run the
daikon.tools.TraceSelect program in the following way:
java -cp ${DAIKONDIR}/daikon.jar daikon.tools.TraceSelect \
num_reps sample_size [options] \
dtrace_file decls_files ... [daikon_options]
num_reps is the number of subsets to create, and sample_size is the number of invocations to collect for each method.
The daikon_options are the same options that can be provided to the
daikon.Daikon program.
The options for TraceSelect are:
Don’t delete the temporary trace samples created by the random selection process. This can help for debugging or for using the tool solely to create trace samples instead of calculating invariants over the samples.
Allows random selection to choose method invocations that entered the method successfully but did not exit normally; either from a thrown Exception or abnormal termination.
Creates an .spinfo file for generating conditional invariants and implications by reporting the invariants that appear in at least one of the samples but not over the entire data set.
Next: Loop invariants, Previous: Enhancing conditional invariant detection, Up: Enhancing Daikon output [Contents][Index]
Abstract types group variables that are used for related purposes in a
program.
For example, suppose that some int variables in your program
are array indices, and other int variables
represent time. Even though these variables have the same type
(int) in the programming language, they have different abstract
types.
Abstract types can be provided as input to Daikon, so that it only infers invariants between values of the same abstract type. This has two benefits. First, it improves Daikon’s performance, often by over an order of magnitude, because it reduces the number of potential invariants that must be checked. Second, it reduces spurious output caused by invariants over unrelated variables. You are strongly recommended to supply abstract types when running Daikon; Daikon does not produce satisfactory output without abstract type information.
Abstract type inference is performed by the front-ends, before Daikon runs. The Daikon distribution includes three tools that infer abstract types (also called comparability types) from program executions.
Previous: Dynamic abstract type inference (DynComp), Up: Enhancing Daikon output [Contents][Index]
Daikon does not by default output loop invariants. Daikon can detect invariants at any location where it is provided with variable values, but currently Daikon’s front ends do not supply Daikon with variable values at loop heads.
You could extend a front end to output more variable values, or you could write a new front end.
Alternately, here is a way to use the current front ends to produce loop invariants. This workaround requires you to change your program, but it requires no change to Daikon or its front ends.
At the top of a loop (or at any other location in the program at which you would like to obtain invariants), insert a call to a dummy procedure that does no work but returns immediately. Pass, as arguments to the dummy procedure, all variables of interest (including local variables). Daikon will produce (identical) preconditions and postconditions for the dummy procedure; these are properties that held at the call site.
For instance, you might change the original code
public void calculate(int x) {
int tmp = 0;
while (x > 0) {
// you desire to compute an invariant here
tmp=tmp+x;
x=x-1;
}
}
into
public void calculate(int x) {
int tmp = 0;
while (x > 0) {
calculate_loophead(x, tmp);
tmp=tmp+x;
x=x-1;
}
}
// dummy procedure
public void calculate_loophead(int x, int tmp) {
}
Next: Tools, Previous: Enhancing Daikon output, Up: Top [Contents][Index]
The Daikon invariant detector is a machine learning tool that finds patterns (invariants) in data. That data can come from any source. A front end is a tool that converts data from some other format into Daikon’s input format.
Daikon is often used to find invariants over variable values in a running program. For that use case, the most common type of front end is an instrumenter. An instrumenter changes a program to add instrumentation (sometimes called probes) so that when the program runs, it does all its usual operations and also produces output to a side file, such as a Daikon .dtrace file (see Reading dtrace files in Daikon Developer Manual).
This chapter describes several front ends that are distributed with Daikon. It is relatively easy to build your own front end, if these do not serve your purpose; we are aware of a number of users who have done so (see Other front ends). For more information about building a new front end, see New front ends in Daikon Developer Manual.
| • Chicory | ||
| • DynComp for Java | ||
| • Kvasir | ||
| • Celeriac | ||
| • dfepl | ||
| • convertcsv.pl | ||
| • Other front ends |
Next: DynComp for Java, Up: Front ends and instrumentation [Contents][Index]
The Daikon front end for Java, named Chicory, executes Java programs, creates data trace (.dtrace) files, and optionally runs Daikon on them. Chicory is named after the chicory plant, whose root is sometimes used as a coffee substitute or flavor enhancer.
While Daikon can be run using only the Chicory front end, it is highly recommend that DynComp be run prior to Chicory. See DynComp for Java for more details.
To use Chicory, run your program as you normally would, but
replace the java command with java daikon.Chicory. For
instance, if you usually run
java -cp myclasspath mypackage.MyClass arg1 arg2 arg3
then instead you would run
java -cp myclasspath:${DAIKONDIR}/daikon.jar daikon.Chicory \
mypackage.MyClass arg1 arg2 arg3
This runs your program and creates file MyClass.dtrace in the current directory. Furthermore, a single command can both create a trace file and run Daikon:
java -cp myclasspath:${DAIKONDIR}/daikon.jar daikon.Chicory \
--daikon mypackage.MyClass arg1 arg2 arg3
See below for more options.
That’s all there is to it! Since Chicory instruments class files
directly as they are loaded into Java,
you do not need to perform separate instrumentation and recompilation steps.
However, you should compile your program with debugging information
enabled (the -g command-line switch to javac);
otherwise, Chicory uses the names arg0, arg1, … as
the names of method arguments.
Chicory must be run in a version 8 (or later) JVM, but it is backward-compatible with older versions of Java code. Chicory can process class files from any version of Java.
| • Chicory options | ||
| • Static fields (global variables) | ||
| • Troubleshooting Chicory |
Next: Static fields (global variables), Up: Chicory [Contents][Index]
Chicory is invoked as follows:
java -cp ${DAIKONDIR}/daikon.jar daikon.Chicory \
chicory-args classname args
where
java classname args
is a valid invocation of Java.
This section lists the optional command-line arguments to Chicory, which appear before the classname on the Chicory command line.
| • Program points in Chicory output | ||
| • Variables in Chicory output | ||
| • Chicory miscellaneous options |
Next: Variables in Chicory output, Up: Chicory options [Contents][Index]
This section lists options that control which program points appear in Chicory’s output.
Only produce trace output for classes/procedures/program points whose names match the given regular expression. This option may be supplied multiple times, and may be used in conjunction with --ppt-omit-pattern.
When this switch is supplied, filtering occurs in the following way: for each program point, Chicory checks the fully qualified class name, the method name, and the the program point name against each regexp that was supplied. If any of these match, then the program point is included in the instrumentation.
Suppose that method bar is defined only in class C. Then to
traces only bar, you could match the method name (in any class)
with regular expression
‘bar$’, or you could match the program point name with ‘C\.bar\(’.
java -cp ${DAIKONDIR}/daikon.jar daikon.Chicory \
--ppt-select-pattern='bar$' ...
java -cp ${DAIKONDIR}/daikon.jar daikon.Chicory \
--ppt-select-pattern='C\.bar\(' ...
Do not produce data trace output for classes/procedures/program points whose names match the given regular expression. This reduces the size of the data trace file and also may make the instrumented program run faster, since it need not output those variables.
This option works just like --ppt-select-pattern does, except that matching program points are excluded, not included.
The --ppt-omit-pattern argument may be supplied multiple times, in order to specify multiple omitting criteria. A program point is omitted if its fully qualified class, fully qualified procedure name, or complete program point name exactly matches one of the omitting criteria. A regular expression matches if it matches any portion of the program point name. Note that currently only classes are matched, not each full program point name. Thus, either all of a class’s methods are traced, or none of them are.
Here are examples of how to avoid detecting invariants over various parts of your program.
java -cp ${DAIKONDIR}/daikon.jar daikon.Chicory \
'--ppt-omit-pattern=^org\.junit\.' ...
java -cp ${DAIKONDIR}/daikon.jar daikon.Chicory \
'--ppt-omit-pattern=^daikon\.util\..*' ...
java -cp ${DAIKONDIR}/daikon.jar daikon.Chicory \
'--ppt-omit-pattern=HashSetLinear\$HslIterator' ...
java -cp ${DAIKONDIR}/daikon.jar daikon.Chicory \
'--ppt-omit-pattern=StackAr.topAndPop()' ...
java -cp ${DAIKONDIR}/daikon.jar daikon.Chicory \
'--ppt-omit-pattern=StackAr.<init>(int):::EXIT33' ...
When this option is chosen, Chicory will record each program point until that program point has been executed sample-cnt times. Chicory will then begin sampling. Sampling starts at 10% and decreases by a factor of 10 each time another sample-cnt samples have been recorded. If sample-cnt is 0, then all calls will be recorded.
Chicory treats classes that match the regex as boot classes. Such classes are not instrumented.
Causes Chicory to output empty dtrace records when static initializers are entered and exited. This is useful for clients that use Chicory to trace method entry and exit.
Next: Chicory miscellaneous options, Previous: Program points in Chicory output, Up: Chicory options [Contents][Index]
This section lists options that control which variables appear in Chicory’s output.
Depth to which to examine structure components (default 2).
This parameter determines which variables the front end causes to be output at
run time. For instance, suppose that a program contained the following
data structures and a method foo:
class A {
int x;
B b;
}
class B {
int y;
int z;
}
class Link {
int val;
Link next;
}
void foo(A myA, Link myList) { ... }
Consider what variables would be output at the entry to method foo:
myA and
myList would be examined; those variables could be determined to
be equal or not equal to other variables.
myA.x, the identity of
myA.b, myList.val, and the identity of myList.next
would be examined.
myA.b.y,
myA.b.z, the identity of myList.next.next, and
myList.next.val would be examined.
Values whose value is undefined are not examined. For instance, if myA
is null on a particular execution of a program point, then
myA.b is not accessed on that execution regardless of the depth
parameter. That variable appears in the .dtrace file, but its
value is marked as nonsensical.
Do not include variables whose name matches the regular expression.
(For static fields, the fully-qualified name is used.)
Variables will be omitted from each program point in which they appear.
Also see Daikon’s --var-omit-pattern command-line argument.
Note that you may need to omit the same variables from downstream tools
that process invariant files, such as Annotate
When this switch is on, Chicory will traverse exactly those fields that are
visible from a given program point. For instance, only the public
fields of class pack1.B will be included at a program point for
class pack2.A whether or not pack1.B is instrumented.
By default, Chicory outputs all fields in instrumented classes (even
those that would not be accessible in Java code at the given program point)
and outputs no fields from uninstrumented classes (even those that are
accessible). When you supply
--std-visibility, consider also supplying --purity-file to
enrich the set of expressions in Daikon’s output.
File pure-methods-file lists the pure methods (sometimes called
observer methods; one type of observer is getter methods)
in a Java program. Pure methods have no externally
side effects, such as setting variables or producing output. For
example, most implementations of the hashCode(),
toString(), and equals() methods are pure.
For each variable, Chicory adds to the trace new fields that represent invoking each pure method on the variable. (Currently, Chicory does so only for pure methods that take no parameters, and obviously this mechanism is only useful for methods that return a value: a pure method that returns no value does nothing!)
Here is an example:
class Point {
private int x, y;
public int radiusSquared() {
return x*x + y*y;
}
}
If radiusSquared() has been specified as pure, then for each point
p, Chicory will output the variables p.x,
p.y, and p.radiusSquared(). Use of pure
methods can improve the Daikon output, since they represent information
that the programmer considered important but that is not necessarily
stored in a variable.
Invoking a pure method at any time in an application should not change the application’s behavior. If a non-pure method is listed in a purity file, then application behavior can change. Chicory does not verify the purity of methods listed in the purity file.
The purity file lists a set of methods, one per line. The format of each method is given by the Sun JDK API:
The string is formatted as the method access modifiers, if any, followed by the method return type, followed by a space, followed by the class declaring the method, followed by a period, followed by the method name, followed by a parenthesized, comma-separated list of the method’s formal parameter types. If the method throws checked exceptions, the parameter list is followed by a space, followed by the word throws followed by a comma-separated list of the thrown exception types. For example:
public boolean java.lang.Object.equals(java.lang.Object)The access modifiers are placed in canonical order as specified by "The Java Language Specification". This is public, protected or private first, and then other modifiers in the following order: abstract, static, final, synchronized native.
By convention, pure-methods-file has the suffix .pure. If pure-methods-file is specified as a relative (not absolute) file name, it is searched for in the configuration directory specified via --configs=directory, or in the current directory if no configuration directory is specified.
One way to create a .pure file is to run the Purity Analysis Kit (https://jppa.sourceforge.net/). If you supply the --daikon-purity-file when running the Purity Analysis Kit, it writes a file that can be supplied to Chicory.
Previous: Variables in Chicory output, Up: Chicory options [Contents][Index]
This section lists all other Chicory options — that is, all options that do not control which program points and variables appear in Chicory’s output.
Print a help message.
Print information about the classes being processed.
Produce debugging information. For other debugging options, run Chicory with the --help option.
Specifies the default name for the trace output (.dtrace) file.
If this is not specified, then the value of the DTRACEFILE
environment variable (at the time the instrumented program runs) is
used. If that environment variable is not used, then the default is
./CLASSNAME.dtrace.gz.
If the DTRACEAPPEND environment
variable is set to any value, the .dtrace file will be appended to
instead of overwritten. Compressed data trace files may not be appended
to. In some cases you may find a single large data trace file more
convenient; in other cases, a collection of smaller data trace files may
give you more control over which subsets of runs to invoke Daikon on.
Note that while Chicory will accept any valid value for filename, it must contain .dtrace to be recognized by Daikon.
This option specifies a declaration file (see Declarations in Daikon Developer Manual) that contains comparability information. This information will be incorporated in the output of Chicory. Any variables not included in the comparability file will have their comparability set so that they are comparable to all other variables of the same type. The DynComp tool is a common source for such a file (see DynComp for Java and DynComp for C/C++).
Write the .dtrace trace output file to the specified directory. The default is the current directory.
Chicory will use this location to search for configuration files. Currently, this only includes *.pure files.
After creating a data trace (.dtrace) file, run Daikon on it. To specify arguments to Daikon use the --daikon-args option. Also see the --daikon-online option.
This option supplies Daikon with a single trace from one execution of your program. By contrast to this option (and --daikon-online), if you invoke Daikon from the command line, you can supply Daikon with as many trace files as you wish.
If the program that Chicory is tracing aborts with an error, then Chicory does not run Daikon, but prints a message such as “Warning: Did not run Daikon because target exited with 1 status”.
This option is like --daikon, except that no .dtrace data trace file is produced. Instead, Chicory sends trace information over a socket to Daikon, which processes the information incrementally (“online”), as Chicory produces it.
Just like with the --daikon option, Daikon is only given a single trace from one execution of your program.
The Kvasir front end also supports online execution, via use of (normal or named) Linux pipes (see Online execution).
Specifies arguments to be passed to Daikon if the --daikon or --daikon-online options are used.
Specifies the maximum size, in bytes, of the memory allocation pool for
the target program. Also applies to Daikon, if the --daikon
command-line argument is given.
The size is specified in the same manner as the
-Xmx switch to java; for example: --heap-size=7g.
Specifies the absolute pathname to the ChicoryPremain.jar file.
Chicory requires this jar file in order to execute. By default Chicory
looks for the jar file in the classpath and in ${DAIKONDIR}/java
(where DAIKONDIR is the
complete installation of Daikon).
Chicory can also use the daikon.jar file for this purpose. If it doesn’t find ChicoryPremain.jar above, it will use daikon.jar itself (if a file named daikon.jar appears in the classpath). If the Daikon jar file is not named daikon.jar, you can use this switch to specify its name. For example:
--premain=C:\lib\daikon-5.8.24.jar
Next: Troubleshooting Chicory, Previous: Chicory options, Up: Chicory [Contents][Index]
Chicory (Daikon’s front end for Java) outputs the values of static fields in the current class, but not in other classes. That means that Daikon cannot report properties over static fields in other classes, because it never sees their values. (By contrast, Kvasir (see Kvasir) supplies the values of C/C++ global variables to Daikon.)
If you need Daikon to include all static variables when processing each class, then ask the maintainers to add that feature to Chicory (or work with them to implement the enhancement). In the meanwhile, here are two workarounds.
Previous: Static fields (global variables), Up: Chicory [Contents][Index]
A message like
Chicory warning: ClassFile: ... - classfile version (49) is out of date and may not be processed correctly.
means that your program uses an old classfile format that is missing
information that Chicory uses during instrumentation. Chicory might work
properly, or it might not. You can eliminate the warning by re-compiling
your program, using a -target command-line argument for a more
recent version of Java. (In the example above, classfile version
49 corresponds to Java 5, which was released in 2004; Java 6 was released
in 2006, and Java 8 was released in 2014.)
Programs that are run via JUnit often benefit from using --ppt-omit-pattern=org.junit as an option to Chicory (and DynComp). This avoids inferring invariants about the JUnit library, which are almost always uninteresting.
Next: Kvasir, Previous: Chicory, Up: Front ends and instrumentation [Contents][Index]
While Daikon can be run using only the Chicory front end, it is highly recommend that DynComp be run prior to Chicory. The DynComp dynamic comparability analysis tool performs dynamic type inference to group variables at each program point into comparability sets (see Program point declarations in Daikon Developer Manual for the file representation of these sets). All variables in each comparability set belong to the same “abstract type” of data that the programmer likely intended to represent, which is a richer set of types than the few basic declared types (e.g., int, float) provided by the language.
Without comparability information, Daikon attempts to find invariants
over all pairs (and sometimes triples) of variables present at every
program point. This can lead to two negative consequences: First, it
may take lots of time and memory to infer all of these invariants,
especially when there are many global or derived variables present.
Second, many of those invariants are true but meaningless because they
relate variables which conceptually represent different types (e.g., an
invariant such as winterDays < year is true but meaningless
because days and years are not comparable).
Consider the example below:
public class Year {
public static void main(String[] args) {
int year = 2005;
int winterDays = 58;
int summerDays = 307;
compute(year, winterDays, summerDays);
}
public static int compute(int yr, int d1, int d2) {
if (0 != yr % 4)
return d1 + d2;
else
return d1 + d2 + 1;
}
}
The three variables in main() all have the same Java
representation type, int, but two of them hold related quantities
(numbers of days), as can be determined by the fact that they interact
when the program adds them, whereas the other contains a conceptually
distinct quantity (a year). The abstract types “day” and “year” are
both represented as int, but DynComp can differentiate them with
its dynamic analysis. For example, DynComp can infer that
winterDays and summerDays are comparable (belong to the
same abstract type) because the program adds their values together
within the compute() function.
Without comparability information, Daikon attempts to find invariants
over all pairs (and sometimes triples) of variables present at every
program point. This can lead to two negative consequences: First, it
may take lots of time and memory to infer all of these invariants,
especially when there are many global or derived variables present.
Second, many of those invariants are true but meaningless because they
relate variables which conceptually represent different types (e.g., an
invariant such as winterDays < year is true but meaningless
because days and years are not comparable).
To use DynComp, run your program as you normally would, but replace the
java command with java daikon.DynComp. For instance,
if you usually run
java -cp myclasspath mypackage.MyClass arg1 arg2 arg3
then instead you would run
java -cp myclasspath:${DAIKONDIR}/daikon.jar daikon.DynComp mypackage.MyClass arg1 arg2 arg3
This runs your program and creates the file MyClass.decls-DynComp in the current directory. The .decls-DynComp file may be passed to Chicory, as described in Detecting invariants in Java programs.
java -cp ${DAIKONDIR}/daikon.jar daikon.Chicory \
--comparability-file=MyClass.decls-DynComp \
mypackage.MyClass arg1 arg2 arg3
See below for more options.
Here is part of a sample .decls-DynComp file generated by running DynComp on the example above:
ppt Year.compute(int, int, int):::ENTER ppt-type enter variable yr var-kind variable dec-type int rep-type int flags is_param comparability 3 variable d1 var-kind variable dec-type int rep-type int flags is_param comparability 2 variable d2 var-kind variable dec-type int rep-type int flags is_param comparability 2 ppt Year.compute(int, int, int):::EXIT11 ppt-type subexit variable yr var-kind variable dec-type int rep-type int flags is_param comparability 3 variable d1 var-kind variable dec-type int rep-type int flags is_param comparability 2 variable d2 var-kind variable dec-type int rep-type int flags is_param comparability 2 variable return var-kind return dec-type int rep-type int comparability 2
The declaration file format is described in Program point declarations in Daikon Developer Manual.
You can cause DynComp to create two additional representations of the comparability information.
Given the option --comparability-file=filename, DynComp outputs comparability sets as sets. The above .decls-DynComp output corresponds to the following comparability-file output:
Daikon Variable sets for Year.compute(int yr, int d1, int d2) enter
[2] [daikon.chicory.ParameterInfo:d1] [daikon.chicory.ParameterInfo:d2]
[1] [daikon.chicory.ParameterInfo:yr]
Daikon Variable sets for Year.compute(int yr, int d1, int d2) exit
[3] [daikon.chicory.ParameterInfo:d1, daikon.chicory.ParameterInfo:
d2, daikon.chicory.ReturnInfo:return]
[1] [daikon.chicory.ParameterInfo:yr]
Given the option --trace-file=filename, DynComp outputs comparability sets as trees, structured such that each variable in the tree has interacted with its children. The lack of a parent-child relationship between two variables in a set does not imply anything about whether they interacted. The above .decls-DynComp output corresponds to the following trace-file output:
Daikon Traced Tree for Year.compute(int yr, int d1, int d2) enter daikon.chicory.ParameterInfo:d1 --daikon.chicory.ParameterInfo:d2 () daikon.chicory.ParameterInfo:yr Daikon Traced Tree for Year.compute(int yr, int d1, int d2) exit daikon.chicory.ParameterInfo:d1 --daikon.chicory.ParameterInfo:d2 (Year:compute(), 11) --daikon.chicory.ReturnInfo:return (Year:compute(), 11) daikon.chicory.ParameterInfo yr
The file here shows that d1, d2, and the return value of
the compute method are in the same comparability set; this is
correct, as they are all of the abstract type “days”. The variable
yr is in its own comparability set; it has abstract type “year”,
and so is not comparable to the other variables. In addition, the structure
of the [d1, d2, return] set shows that at some point, d1 interacted
with d2, and that d2 interacted with return. The absence of
a d1 -- return edge does not imply that d1 and return never
interacted directly.
In addition, non-root nodes in the trace trees can indicate a list of class names,
method names, and line numbers at which values interacted, resulting in comparability
between the preceding child node and its parent. In the above example, d1
interacted with d2 on line 11 of the compute method of the Year
class.
Duplicate values in this list represent the results of separate calls to
another method which each of the relevant variables. For example, if we modify
the sample to use global variables instead of locals and add an additional call
to compute:
public class Year2 {
static int year = 2005;
static int winterDays = 58;
static int summerDays = 307;
static int schoolDays = 180;
static int breakDays = 185;
public static void main(String[] args) {
compute(year, winterDays, summerDays);
compute(year, schoolDays, breakDays);
}
public static int compute(int yr, int d1, int d2) {
if (0 != yr % 4)
return d1 + d2;
else
return d1 + d2 + 1;
}
}
then for compute we might see
this output:
DynComp Traced Tree for Year2.compute(int yr, int d1, int d2) exit daikon.chicory.FieldInfo:Year2.schoolDays --daikon.chicory.FieldInfo:Year2.breakDays (Year2:compute(), 14) --daikon.chicory.ParameterInfo:d1 (Year2:compute(), 14) ----daikon.chicory.FieldInfo:Year2.winterDays (Year2:compute(), 14) ------daikon.chicory.FieldInfo:Year2.summerDays (Year2:compute(), 14) ------daikon.chicory.ParameterInfo:d2 (Year2:compute(), 14) ------daikon.chicory.ReturnInfo:return (Year2:compute(), 14)
Empty lists indicate that no non-assignment interactions occurred in the series of interactions connecting the two variables.
Elements of these lists are essentially parts of stack traces. The maximum number of stack trace levels displayed is set by --trace-line-depth, which is equal to 1 by default.
For these files, DynComp also has a --abridged-vars option that replaces text
like daikon.chicory.ParameterInfo:d2 with text like Parameter d2 in the comparability-file
and trace-file. It writes this instead of
daikon.chicory.ThisObjInfo:this; and return instead of
daikon.chicory.ReturnInfo:return. This option is off by default, but can be
turned on with --abridged-vars.
| • Instrumenting the JDK with DynComp | ||
| • DynComp for Java options | ||
| • Instrumentation of Object methods | ||
| • Troubleshooting DynComp for Java | ||
| • DynComp for Java known bugs |
Next: DynComp for Java options, Up: DynComp for Java [Contents][Index]
If you did not already do so when installing Daikon (see Installing Daikon), follow the instructions here to build an instrumented copy of the JDK. Use the following command:
make -C ${DAIKONDIR}/java dcomp_rt.jar
Either the JAVA_HOME environment variable must be set, or
javac must be on the execution path.
This command instruments the classes in the
rt.jar file of the JDK, and creates a new file,
dcomp_rt.jar, in the java directory.
Building dcomp_rt requires 10-30 minutes to complete and uses 1024 MB of memory. Regular progress indicators are printed to standard output.
You can ignore warnings issued during the instrumentation process, so long as the make target itself completes normally.
If there are any methods in the JDK that DynComp is unable to instrument, their names will be printed at the end of the instrumentation process. This is not a problem unless your application calls one of these methods (directly or indirectly). If one of these methods is called, a ‘NoSuchMethodException’ will be generated when the call is attempted.
If the instrumented JDK is in a non-standard location, use the --rt-file switch to specify its location, or change your classpath to include it.
One final note: if you update your JDK in any way (such as an OS upgrade), you will need to rebuild dcomp_rt.jar.
Next: Instrumentation of Object methods, Previous: Instrumenting the JDK with DynComp, Up: DynComp for Java [Contents][Index]
DynComp is invoked as follows:
java -cp myclasspath:${DAIKONDIR}/daikon.jar daikon.DynComp dyncomp-args classname args
where
java classname args
is a valid invocation of Java.
This section lists the optional command-line arguments to DynComp, which appear before the classname on the DynComp command line.
Print a help message.
Print information about the classes being processed.
Dump the instrumented class files to the bin subdirectory of the directory specified by --debug-dir. Dump the original, uninstrumented class files to the orig subdirectory of the directory specified by --debug-dir. If --debug-dir is not specified, it defaults to debug/ in the current working directory.
Produce debugging information. (This produces a lot of output!) This option also turns on --dump.
The directory in which to dump instrumented class files (only if dump or --debug is specified). Defaults to debug in the current working directory.
The directory in which to create output files. Defaults to the current working directory.
Output filename for .decls file suitable for input to Chicory. Defaults to target_program.decls-DynComp.
Output filename for a more easily human-readable file summarizing comparability sets. The file is intended primarily for debugging. It is not meant to be used as input to Chicory’s --comparability-file option; use the output from DynComp’s --decl-file option for that.
If specified, write a human-readable file showing some of the interactions that occurred. The file is intended primarily for debugging.
Controls size of the stack displayed in tracing the interactions that occurred. Default behavior is to only display one element in the stack — that is, display at most the topmost function on the stack when the interaction occurred. This switch has no effect if --trace-file is not specified, or is null.
When this switch is on, DynComp abridges the variables printed in the files specified by --comparability-file and --trace-file. For example, DynComp will output ‘Field foo’ instead of ‘dyncomp.chicory.FieldInfo:MyClass.foo’. In particular, it replaces ‘dyncomp.chicory.ReturnInfo:return’ with ‘return’ and ‘dyncomp.chicory.ThisObjInfo:this’ with ‘this’.
Only emit program points that match regex. Specifically, a program point is considered to match regex if the fully qualified class name, the method name, or the program point name matches regex. The behavior of this switch is the same as in Chicory (see Program points in Chicory output).
This option can be specified multiple times, and may be used in conjunction with --ppt-omit-pattern. If a program point matches both a select pattern and an omit pattern, it is omitted.
Suppress program points that match regex. Specifically, a program point is considered to match regex if the fully qualified class name, the method name, or the program point name matches regex. The behavior of this switch is the same as in Chicory (see Program points in Chicory output).
This option can be specified multiple times, any may be used in conjunction with --ppt-select-pattern. If a program point matches both a select pattern and an omit pattern, it is omitted.
Specifies the location of the instrumented JDK (see Instrumenting the JDK with DynComp). This option is rarely necessary, because if --rt-file is not specified, DynComp will search for a file named dcomp_rt.jar along the classpath, and in ${DAIKONDIR}/java. Both this file and the current classpath are placed on the boot classpath for DynComp’s execution.
If the filename is NONE, then
run DynComp with an uninstrumented JDK, instead of with a
copy of the JDK that has been instrumented with DynComp.
This will improve run-time performance, but will
yield less accurate results.
When this switch is on, DynComp traverses exactly those fields that are visible from a given program point. For an example, see Variables in Chicory output.
Depth to which to examine structure components (default 2). This parameter determines which variables the front end causes to be output at run time. For an example, see Variables in Chicory output.
Specifies the absolute pathname to the dcomp_premain.jar file.
DynComp requires this jar file in order to execute. By default DynComp
looks for the jar file in the classpath and in ${DAIKONDIR}/java
(where DAIKONDIR is the
complete installation of Daikon).
DynComp can also use the daikon.jar file for this purpose. If it doesn’t find dcomp_premain.jar above, it will use daikon.jar itself (if a file named daikon.jar appears in the classpath). If the Daikon jar file is not named daikon.jar, you can use this switch to specify its name. For example:
--premain=C:\lib\daikon-5.8.24.jar
Next: Troubleshooting DynComp for Java, Previous: DynComp for Java options, Up: DynComp for Java [Contents][Index]
DynComp is unable to directly instrument methods of the class
Object, such as clone and equals. DynComp uses a
few tricks, described here in brief, to track comparability in these
methods.
Calls such as o1.equals(o2) are replaced with calls to a static
method in DynComp, dcomp_equals(o1, o2). This static method
dynamically determines whether or not o1 is an instance of a
class that has been instrumented by DynComp; every such class
implements the interface DCompInstrumented. If so, it attempts
to invoke the instrumented version of the equals method for
o1. If not, or if o1 has not overridden the
equals method from Object, then no instrumented version
exists, so the uninstrumented version is invoked.
In either case, the references o1 and o2 are considered
to be comparable. In a future release, we will provide a command-line
switch to customize this behavior.
The clone method operates in a similar manner, choosing
dynamically to invoke the instrumented method or the uninstrumented
method. In the case of clone, the methods are invoked via
reflection. In either case, the object being cloned and the resulting
clone are made comparable to each other. Again, we will provide a
switch to customize this behavior in a future release.
Next: DynComp for Java known bugs, Previous: Instrumentation of Object methods, Up: DynComp for Java [Contents][Index]
If DynComp crashes the JVM, then the most likely problem is that you are running with a wrong version of the JDK. Re-instrument the JDK as described in Instrumenting the JDK with DynComp.
Examples of errors that you may obtain when using the wrong version of the JDK include the following:
Error occurred during initialization of VM java.lang.UnsatisfiedLinkError:
# A fatal error has been detected by the Java Runtime Environment: # # SIGSEGV
When running DynComp, an exception similar to the following:
Exception in thread "main" java.lang.AbstractMethodError:
example1c$$Lambda$5/1722023916.sayHello(Ldaikon/dcomp/DCompMarker;)Ljava/lang/String;
probably means that sayHello is the method of an functional
interface that has not been annotated with @FunctionalInterface.
Previous: Troubleshooting DynComp for Java, Up: DynComp for Java [Contents][Index]
This is relevant to frameworks such as JUnit that call code reflectively.
If you want to run tests using JUnit, then explicitly create a Suite that
contains the tests you want to run, rather than annotating methods with
@Test and depending on JUnit to find them and call them via reflection.
If you are generating JUnit test suites with
Randoop, then supply the
--junit-reflection-allowed=false command-line option to Randoop.
Programs that are run via JUnit often benefit from using --ppt-omit-pattern=org.junit as an option to Chicory (and DynComp). This avoids inferring invariants about the JUnit library, which are almost always uninteresting.
clone() method may fail on particular
invocations within private classes in the JDK.
Next: Celeriac, Previous: DynComp for Java, Up: Front ends and instrumentation [Contents][Index]
Daikon’s front end for C and C++, named Kvasir, executes C and C++ programs and creates data trace (.dtrace) files of variables and their values by examining the operation of the binary at run time. Kvasir is named after the Norse god of knowledge and beet juice. It is built upon the Fjalar dynamic analysis framework for C and C++ programs (available at http://groups.csail.mit.edu/pag/fjalar/, but already included in the Daikon distribution).
To use Kvasir, first compile your program using either the DWARF-2 or DWARF-3 debugging
format (e.g., supply the -gdwarf-3 option to gcc) and
without optimizations (e.g., supply the -O0 option to gcc).
Also, some versions of gcc now output position independent code by default.
Kvasir cannot properly process these binaries.
You must add the -no-pie option to disable this feature.
Note that if your build system separates the compile and link steps, the
-no-pie option needs to be on the link step.
Then, prefix your command line by kvasir-dtrace. For example,
if you normally run your program with the command
./program -option input.file
then instead use the command
kvasir-dtrace ./program -option input.file
to run your program and create a data trace file daikon-output/program.dtrace, which can be fed as input into Daikon. You can perform this step multiple times to create multiple data trace files for Daikon. You can also run Daikon without creating an intermediate data trace file; see Online execution.
For information about installing Kvasir, see Installing Kvasir. Kvasir only works under Linux running on an x86-64 processor (also known as an amd64 processor); for full details, see Kvasir limitations. When you run Kvasir, if you get a message of the form:
valgrind: failed to start tool 'fjalar' for platform 'x86-linux': No such file or directory
it indicates that your program is not an x86-64 binary. See Running Kvasir on i386 binaries for information on how to run Kvasir on an i386 compatible binary. For information about how to create an instrumenter for C that works on non-Linux or non-x86 platforms, see Instrumenting C programs in Daikon Developer Manual.
Next: Kvasir options, Up: Kvasir [Contents][Index]
Before using Kvasir, you must compile your program compile and link your program normally, with two exceptions:
gcc default DWARF output level is now 5.
Therefore, you must supply the -gdwarf-2 or -gdwarf-3 command line option.
In the second step of using Kvasir, run your program as you normally
would, but prepend the command kvasir-dtrace to the beginning.
For instance, if you normally run your program with the command
./myprogram -option input.file
just say
kvasir-dtrace ./myprogram -option input.file
As well as running your program (more slowly than usual), this command also creates a directory daikon-output in the current directory containing a program.dtrace file suitable as input to Daikon.
Kvasir’s first argument, the program name, should be given as a pathname, as shown above. If you usually just give a program name that is not in the current directory but is found in your path, you may need to modify your command to specify a pathname. For example:
kvasir-dtrace `which myprogram` -option input.file
You may supply options to Kvasir before the argument that is the name of your program (see Kvasir options).
Next: DynComp for C/C++, Previous: Using Kvasir, Up: Kvasir [Contents][Index]
To see a complete list of options, run this command: kvasir-dtrace --help
Output file format:
Write the .decls file listing the names of functions and variables (called declarations) to the specified file name. This forces Kvasir to generate separate .decls and .dtrace files instead of outputting everything to the .dtrace file, which is the default behavior. If only a .dtrace file is created (default behavior), then it contains both variable declarations and a trace of values. If separate .decls and .dtrace files are created, then the .decls file contains declarations and the .dtrace file contains the trace of values. Note that while Kvasir will accept any valid value for filename, it must contain .decls to be recognized by Daikon.
Exit after writing the .decls file; don’t run the program or generate trace information. Since the .decls file is the same for any run of a program, it can be generated once and then reused on later runs, as long as no new program points are added and each program point has the same set of variables.
Write the .dtrace trace file to the specified file name. The default is daikon-output/programname.dtrace, where programname is the name of the program. A filename of - may be used to specify the standard output; in this case, the regular standard output of the program will be redirected back to the terminal (/dev/tty), to avoid intermixing it with the trace output. If the given filename ends in .gz, then --dtrace-gzip is enabled and the .dtrace file will be compressed. Note that while Kvasir will accept any valid value for filename, it must contain .dtrace to be recognized by Daikon.
By default, the .dtrace file contains both a list of variable declarations followed by a trace of variable values (see File formats in Daikon Developer Manual). If this option is used, then variable declarations are not outputted in the .dtrace file. This option is equivalent to --decls-file=/dev/null, except that it runs faster. This is useful when you want to generate one copy of the declarations in the .decls file using --decls-only, generate many .dtrace files from different program runs, and then feed 1 .decls and several .dtrace files into Daikon.
Append new trace information to the end of an existing .dtrace file. The default is to overwrite a preexisting .dtrace file. When this option is used, no declaration information is written because it is assumed that the existing .dtrace file already contains all declarations (Daikon does not accept duplicate declarations).
Compress trace information with the gzip program before writing
it to the .dtrace file. You must have the gzip program
available.
Create the output .dtrace file as a FIFO (also known as a named pipe). Kvasir will then open first the .decls FIFO and then the .dtrace FIFO, blocking until another program (such as Daikon) reads from them. Using FIFO files for the output of Kvasir avoids the need for large trace files, but FIFO files are not supported by some file systems, including the Andrew File System (AFS).
Redirect the standard output (respectively, standard error) stream of the
program being traced to the specified path. By default, the standard
output and standard error streams will be left pointing to the same
locations specified by the shell, except that if --dtrace-file=-
is specified, then the default behavior is as if
--program-stdout=/dev/tty were specified, since mixing the
program’s output and Kvasir’s trace output is not advisable.
If the same filename is given for both options, the streams will be
interleaved in the same way as if by the Bourne shell construction
2>&1.
Also, as in the shell, filename can be an ampersand followed by an integer, to redirect to a numbered file descriptor. For instance, to redirect the program’s standard output and error, and Kvasir’s standard error, to a single file, you can say --program-stdout='&2' --program-stderr='&2' 2>filename.
Selective program point and variable tracing:
Trace only the program points (respectively, variables) listed in the given file. Other program points (respectively variables) will be omitted from the .decls and .dtrace files. A convenient way to produce such files is by editing the output produced by the --dump-ppt-file (respectively, --dump-var-file) option described below (see Tracing only part of a program).
Print a list of all the program points (respectively all the variables) in the program to the specified file. An edited version of this file can then be used with the --ppt-list-file (respectively --var-list-file) option (see Tracing only part of a program). Note: You must use these options with the --no-dyncomp option because otherwise, the behavior is undefined. Running Kvasir with these options will initialize but not actually execute the target program, so the dynamic comparability analysis cannot be performed in the first place.
Omit any global or static variables from the .decls and .dtrace files. Leaving these out can significantly improve Kvasir and Daikon’s performance, at the expense of missing properties involving them. The default is to generate trace information for global and static variables.
Omit any static variables but generate trace information for global variables in the .decls and .dtrace files.
Output all static variables at all program points in the .decls and .dtrace files. By default, file-static variables are only outputted at program points for functions that are defined in the same file (compilation unit) as the variable, and static variables declared within a particular function are only outputted at program points for that function. These heuristics decrease clutter in the output without greatly reducing precision because functions have no easy way of modifying variables that are not in-scope, so it is often not useful to output those variables. This option turns off these heuristics and always outputs static variables at all program points.
Other options affecting the amount of output Kvasir produces:
Enables printing of object program points for C/C++ structs and C++ classes. See Program points for more information.
This option forces the flattening of statically-sized arrays into
separate variables, one for each element. For example, an array
foo of size 3 would be flattened into 3 variables: foo[0],
foo[1], foo[2]. By default, Kvasir flattens
statically-sized arrays only after it has already exhausted the one
level of sequences that Daikon allows in the .dtrace output format
(e.g. an array of structs where each struct contains a statically-sized
array).
Only visit at most the first N elements of all arrays. This can improve performance at the expense of losing coverage; it is often useful for tracing selected parts of programs that use extremely large arrays or memory buffers.
This option forces Kvasir to output .decls and .dtrace entries for struct variables. By default, Kvasir ignores struct variables because there is really no value that can be meaningfully associated with these variables. However, some tools require struct variables to be outputted, so we have included this option. Struct variables are denoted by a ‘# isStruct=true’ annotation in their declarations.
For recursively-defined structures (structs or classes with members that are structs or classes or pointers to structs or classes of any type), N (an integer between 0 and 100) specifies approximately how many levels of pointers to dereference. This is useful for controlling the output of complex data structures with many references to other structures. The default is 2.
For recursively-defined structures (structs or classes with members that are pointers to the same type of struct or class), N (an integer between 0 and 100) specifies approximately how many levels of pointers to dereference. This is useful for controlling the output of linked lists and trees. The default is 4. If you are trying to traverse deep into data structures, try adjusting the --struct-depth and --total-depth options until Kvasir traverses deep enough to reach the desired variables.
Specifies the name of the pointer type disambiguation file (see Pointer type disambiguation). If this file exists, Kvasir uses it to make decisions about how to output the referents of pointer variables. If the file does not exist, then Kvasir creates it. This file may then be edited and used on subsequent runs. This option initializes but does not fully execute the target program (unless it is run with the --smart-disambig option).
Tells Kvasir to create or read pointer type disambiguation (see Pointer type disambiguation) with the default filename, which is myprog.disambig in the same directory as the target program, where myprog is the name of the target program. This is equivalent to --disambig-file=myprog.disambig.
This option should be used in addition to either the --disambig or --disambig-file options (it does nothing by itself). If the .disambig file specified by the option does not exist, then Kvasir executes the target program, observes whether each pointer refers to either one element or an array of elements, and creates a disambiguation file that contains suggestions for the disambiguation types of each pointer variable. This potentially provides more accuracy than using either the --disambig or --disambig-file options alone, but at the expense of a longer run time. (If the .disambig file already exists, then this option provides no extra functionality.)
By default, Kvasir treats all pointers as arrays when outputting their contents. This option forces Kvasir to treat function parameters and return values that are pointers as pointing to single values. However, all pointers nested inside of data structures pointed-to by parameters and return values are still treated as arrays. This is useful for outputting richer data information for functions that pass parameters or return values via pointers, which happens often in practice.
By default, Kvasir treats all pointers as arrays when outputting their contents. This option forces Kvasir to treat all pointers as pointing to single values. This is useful when tracing nested structures with lots of pointer fields which all refer to one element.
Run Kvasir with the DynComp dynamic comparability analysis tool to determine which variables have the same abstract type. (This is the default behavior for Kvasir and it is not necessary to specify this option.) Variable comparability information improves the performance of Daikon and improves Daikon’s output by filtering out irrelevant invariants. Because it is not available until the end of execution, comparability information is always written to a separate .decls file (in the format specified in the Program point declarations in Daikon Developer Manual), as if the --decls-file option had been specified (--decls-file can still be used to control the name of the file). This file must be provided to Daikon along with the .dtrace file. This option may also be used with --decls-only to only generate a .decls file without a .dtrace.
Note that if you are running multiple runs (executions) of your test program and you are certain that the comparability information will not vary from run to run, you may use --no-dyncomp on the second and subsequent runs to reduce the time required to generate the .trace file(s).
By default, DynComp considers any binary operation as an interaction between its two operands. (=all)
You may restrict this such that the only binary operations that qualify as interactions are comparisons, addition, subtraction. This ensures that the variables that DynComp groups together into one set all have the same units (e.g., physics units). (=units)
A tighter restriction is to stipulate that the only binary operations that
qualify as interactions are comparisons between values (e.g., x <=
y or x != y). (=comparisons)
Finally, you may specify that no binary operations qualify as interactions between values. Thus, DynComp only tracks dataflow. (=none)
This option applies an approximation for handling literal values which greatly speeds up the performance of DynComp and drastically lowers its memory usage, but at the expense of a slight loss in precision of the generated comparability sets. If you cannot get DynComp to successfully run on a large program, even after tweaking --dyncomp-gc-num-tags, try turning on this option.
This option runs a more detailed (but more time- and space-intensive) algorithm for tracking variable comparability. It takes O(n^2) time and space, whereas the default algorithm takes roughly O(n) time and space. However, it can produce more precise results. Despite its name, this mode can be used together with --dyncomp-fast-mode to run the more precise algorithm but still use an approximation for handling literal values. (This mode is still experimental and not well-tested yet.)
The default behavior for DynComp is to generate the same comparability numbers for Daikon variables at each pair of function entrance and exit program points. If this option is used, then DynComp keeps track of comparability separately for function entrances and exits, which can lead to more accurate results, but sometimes generates output .decls files that Daikon cannot accept.
By default, DynComp runs a garbage collector for the tag metadata once after every 10,000,000 tags have been assigned. This option tells the garbage collector to run once after every N tags have been assigned. Making the value of N larger allows your program to run faster (because the garbage collector runs less frequently), but may cause your program to run out of memory as well. Making the value of N too small may cause your program to never terminate if N is smaller than the total number of tags that your program uses in steady state. You will probably need to experiment with tweaking this value in order to get DynComp to work properly.
Making the value of N equal to 0 turns off the garbage collector. This may reduce your program’s execution time; however, it is not recommended for long program runs, because without the garbage collector, it will likely run out of memory.
Debugging:
Outputs a representation of data structures, functions, and variables in the target program to an XML file in order to aid in debugging. These are all the entities that Kvasir tracks for a particular run of a target program, so if you do not see an entity in this XML file, then you should either adjust command-line options or contact us with a bug report.
This pauses the program’s execution in an infinite loop during
initialization. You can attach a debugger such as gdb to the
running process by running gdb on inst/lib/valgrind/fjalar-amd64-linux under
the Kvasir directory and using the attach command.
Enable progress messages meant for debugging problems with Kvasir, Fjalar, or DynComp. By default, they are disabled. This option is intended mainly for Kvasir’s developers.
Enables trace messages to be output to stderr. These are disabled by
default. These options are intended mainly for DynComp developers.
Next: Tracing only part of a program, Previous: Kvasir options, Up: Kvasir [Contents][Index]
By default, Kvasir outputs both a .dtrace file that contains value traces, and a .decls file with variable comparability information that was produced by the DynComp tool. You can run Daikon on just the .dtrace file without the DynComp variable comparability information, but doing so is strongly discouraged.
The DynComp dynamic comparability analysis tool performs dynamic type inference to group variables at each program point into comparability sets. (See Program point declarations in Daikon Developer Manual, for the file representation format of these sets.) All variables in each comparability set belong to the same “abstract type” of data that the programmer likely intended to represent, which is a richer set of types than the few basic declared types (e.g., int, float) provided by the language. Consider the example below:
int main() {
int year = 2005;
int winterDays = 58;
int summerDays = 307;
compute(year, winterDays, summerDays);
}
int compute(int yr, int d1, int d2) {
if (yr % 4)
return d1 + d2;
else
return d1 + d2 + 1;
}
The three variables in main() all have the same C representation
type, int, but two of them hold related quantities (numbers of
days), as can be determined by the fact that they interact when the
program adds them, whereas the other contains a conceptually distinct
quantity (a year). The abstract types “day” and “year” are both
represented as int, but DynComp can differentiate them with its
dynamic analysis. For example, DynComp can infer that winterDays
and summerDays are comparable (belong to the same abstract type)
because the program adds their values together within the
compute() function.
Without comparability information, Daikon attempts to find invariants
over all pairs (and sometimes triples) of variables present at every
program point. This can lead to two negative consequences: First, it
may take lots of time and memory to infer all of these invariants,
especially when there are many global or derived variables present.
Second, many of those invariants are true but meaningless because they
relate variables which conceptually represent different types (e.g., an
invariant such as winterDays < year is true but meaningless
because days and years are not comparable).
By default, Kvasir runs with DynComp to generate a .decls file with comparability information along with the usual value trace in the .dtrace file. Using --decls-only will only generate the .decls file without the extra slowdown of writing the .dtrace file to disk (however, because DynComp must execute the entire program to perform its analysis, the only time saved is I/O time). Other DynComp options are listed in the Kvasir options section. Running Kvasir with DynComp takes more memory and longer time than Kvasir without DynComp, but Daikon will run faster and produce better output. Furthermore, it is possible to run DynComp only once to generate a .decls file with comparability information, and pass that one file into Daikon along with many different .dtrace files generated during subsequent Kvasir runs without DynComp. You may wish to verify that your .decls file information does not vary from run to run if you choose to use this approach. The .decls-DynComp files should be identical.
Here is part of the .decls file generated by running Kvasir with DynComp on the above example:
ppt ..compute():::ENTER
ppt-type enter
variable yr
var-kind variable
rep-type int
dec-type int
flags is_param
comparability 1
variable d1
var-kind variable
rep-type int
dec-type int
flags is_param
comparability 2
variable d2
var-kind variable
rep-type int
dec-type int
flags is_param
comparability 2
ppt ..compute():::EXIT0
ppt-type subexit
variable yr
var-kind variable
rep-type int
dec-type int
flags is_param
comparability 1
variable d1
var-kind variable
rep-type int
dec-type int
flags is_param
comparability 2
variable d2
var-kind variable
rep-type int
dec-type int
flags is_param
comparability 2
variable return
var-kind variable
rep-type int
dec-type int
comparability 2
The abstract type of “year” (and its corresponding comparability set) is
represented by the number 1 while the abstract type of “day” is
represented by the number 2. DynComp places two variables in the same
comparability set when their values interact via program operations such
as arithmetic or assignment. Because the parameters d1 and
d2 were added together, DynComp inferred that those variables
were somehow related and put them in the same comparability set. The
return value is also related to d1 and d2 because it is
the result of the addition operation. Notice that yr never
interacts with any other variables, so DynComp places it into its own
comparability set. With this comparability information, Daikon will
never attempt to find invariants between yr and
d1/d2, which both saves time and memory and eliminates
meaningless invariants (the savings are minuscule in this trivial
example, but they can be rather dramatic in larger examples).
Next: Pointer type disambiguation, Previous: DynComp for C/C++, Up: Kvasir [Contents][Index]
When Kvasir is run on a target program of significant size, often times too much output is generated, which causes an enormous performance slowdown of both Kvasir outputting the trace file and also Daikon trying to process the trace file. It is often desirable to only trace a specific portion of the target program, program points and variables that are of interest for a particular invariant detection application. For instance, one may only be interested in tracking changes in a particular global data structure during calls to a specific set of functions (program points), and thus have no need for information about any other program points or variables in the trace file. The --ppt-list-file and --var-list-file options can be used to achieve such selective tracing.
The program point list file (abbreviated as ppt-list-file)
consists of a newline-separated list of names of functions that the
user wants Kvasir to trace. Every name corresponds to both the entrance
(:::ENTER) and exit (:::EXIT) program points for that function
and is printed out in the exact same format that Kvasir
uses for that function in the trace file. (See Using Kvasir,
for the program point naming scheme.) Here is an
example of a ppt-list-file:
FunctionNamesTest.cpp.staticFoo(int, int) ..firstFileFunction(int) ..main() second_file.cpp.staticFoo(int, int) ..secondFileFunction()
It is very important to follow this format in the ppt-list-file
because Kvasir performs string comparisons to determine which program
points to trace. Thus, it is often easier to have Kvasir generate a
ppt-list-file file that contains a list of all program points in a
target program by using the --dump-ppt-file option, and then
either comment out (by using the ‘#’ comment character at the
beginning of the line) or delete lines in that file for program points
not to be traced or create a new ppt-list-file using the names in
the Kvasir-generated file. This prevents typos and the tedium of
manually typing up program point names. In fact, the ppt-list-file
presented in the above example was generated from a C++ test program named
FunctionNamesTest by using the following command:
kvasir-dtrace --dump-ppt-file=FunctionNamesTest.ppts \
./FunctionNamesTest
That file represents all the program points that Kvasir would
normally trace. If the user wanted to only trace the main()
function, he could comment out all other lines by placing a single
‘#’ character at the beginning of each line to be commented out,
as demonstrated here:
#FunctionNamesTest.cpp.staticFoo(int, int) #..firstFileFunction(int) ..main() #second_file.cpp.staticFoo(int, int) #..secondFileFunction()
When running Kvasir with the --ppt-list-file option using this
as the ppt-list-file, Kvasir only stops the execution of the target program at the
entrance and exit of main() in order to output values to the
.dtrace file. In order to reduce the file size, when running Kvasir
with the --ppt-list-file option, the .decls file only contains
program point declarations for those listed in the ppt-list-file
(..main():::ENTER and ..main():::EXIT in this case) because
no other declarations are necessary.
The variable list file (abbreviated as var-list-file) contains all of the variables that the user wants Kvasir to output. There is one section for global variables and a section for variables associated with each function (formal parameters and return values). Again, the best way to create a var-list-file is to have Kvasir generate a file with all variables using the --dump-var-file option and then modifying that file for one’s particular needs by either deleting or commenting out lines (again using the ‘#’ comment character). For example, executing
kvasir-dtrace --dump-var-file=FunctionNamesTest.vars \
./FunctionNamesTest
will generate the following var-list-file named
FunctionNamesTest.vars:
----SECTION---- globals /globalIntArray /globalIntArray[] /anotherGlobalIntArray /anotherGlobalIntArray[] ----SECTION---- FunctionNamesTest.cpp.staticFoo() x y ----SECTION---- ..firstFileFunction(int) blah ----SECTION---- ..main() argc argv argv[] return ----SECTION---- second_file.cpp.staticFoo() x y ----SECTION---- ..secondFileFunction()
The file format is straightforward. Each section is marked by a
special string ‘----SECTION----’ on a line by itself followed
immediately by a line that either denotes the program point name
(formatted like how it appears in the .decls and .dtrace files) or the
special string ‘globals’. This is followed by a
newline-delimited list of all variables to be outputted for that
particular program point. Global variables listed in the
globals section are outputted for all program points. Additional global
variables to be outputted for a particular program point can be specified
in the corresponding section entry. For clarity, one or more blank lines
should separate neighboring sections, although the ‘----SECTION----’
string literal on a line by itself is the only required delimiter.
If an entire section is missing, then no variables for that program point
(or no global variables, if it is the special globals section) are traced.
The variables listed in this file are written exactly as they appear in
the .decls and .dtrace file. (See Using Kvasir,
for the variable naming scheme.) In the program that generated the
output for the above example, int*
globalIntArray is a global integer pointer variable. For that
variable, Kvasir generates two Daikon variables: /globalIntArray
to represent the hashcode pointer value, and /globalIntArray[] to
represent the array of integers referred-to by that pointer. The
latter is a derived-variable that can be thought of as the child of
/globalIntArray. If the entry for /globalIntArray is
commented-out or missing, then Kvasir will not output any values for
/globalIntArray or for any of its children, which in this case is
/globalIntArray[]. If a struct or struct pointer variable is
commented-out or missing, then none of its members are traced. Thus, a
general rule about variable entries in the var-list-file is that
if a parent variable is not present, then neither it nor its children
are traced.
record record->entries[1] record->entries[1]->list record->entries[1]->list->head record->entries[1]->list->head->magic
For example, if you wanted to trace the value of the magic field
nested deep within several layers of structs and arrays, it would not be
enough to merely list this variable in the var-list-file. You
would need to list all variables that are the parents of this one, as
indicated by their names. This can be easily accomplished by creating a
file with --dump-var-file and cutting out variable entries,
taking care to not cut out entries that are the parents of entries that
you want to trace.
In order to limit both the number of program points traced as well as the variables traced at those program points, the user can run Kvasir with both the --ppt-list-file and --var-list-file options with the appropriate ppt-list-file and var-list-file, respectively. The var-list-file only needs to contain a section for global variables and sections for all program points to be traced because variable listings for program points not to be traced are irrelevant (their presence in the var-list-file does not affect correctness but does cause an unnecessary performance and memory inefficiency).
If the --dump-var-file option is used in conjunction with the --ppt-list-file option, then the only sections generated in the var-list-file will be the global section and sections for all program points explicitly mentioned in the ppt-list-file. This is helpful for generating a smaller var-list-file for use with an already-existent ppt-list-file.
Next: C++ support, Previous: Tracing only part of a program, Up: Kvasir [Contents][Index]
Kvasir permits users (or external analyses) to specify whether pointers refer to arrays or to single values, and optionally, to specify the type of a pointer (see Pointer type coercion). For example, in
void sum(int* array, int* result) { ... } // definition of "sum"
...
int a[40];
int total;
...
sum(a, &total); // use of "sum"
the first pointer parameter refers to an array while the second refers to
a single value. Kvasir (and Daikon) should treat these values
differently. For instance, *array is better printed as array[],
an array of integers, and result[] isn’t a sensible array
at all, even though in C result[0] is semantically identical to
*result.
By default, Kvasir treats all pointers as referencing arrays. For
instance, it would print result[] rather than result[0]
and would indicate that the length of array result[] is always 1.
In order to improve the formatting of Daikon’s output (and to speed it
up), you can indicate to Kvasir that certain pointers refer to single
elements rather than to arrays.
For an example, see Pointer type disambiguation example.
For a list of command-line options that are related to pointer type
disambiguation, see Pointer type disambiguation command-line arguments.
Information about whether each pointer refers to an array or a single element can be specified in a .disambig file that resides in the same directory as the target program (by default). The --disambig option instructs Kvasir to read this file if it exists. (If it does not exist, Kvasir produces the file automatically and, if invoked along with the --smart-disambig option, heuristically infers whether each pointer variable refers to single or multiple elements. Thus, users can edit this file for use on subsequent runs rather than having to create it from scratch.) The .disambig file lists all the program points and user-defined types, and under each, lists certain types of variables along with their custom disambiguation types as shown below. The list of disambiguation options is:
char and unsigned char:
char and unsigned for unsigned char. (Default)
char and unsigned char:
The .disambig file that Kvasir creates contains a section for each function, which can be used to disambiguate parameter variables visible at that function’s entrance program point and parameter and return value variables visible at that function’s exit program point. It also contains a section for every user-defined struct/class, which can be used to disambiguate member variables of that struct/class. Disambiguation information entered here will apply to all instances of a struct/class of that type, at all program points. There is also a section called “globals”, which disambiguates global variables which are output at every program point. The entries in the .disambig file may appear in any order, and whole entries or individual variables within a section may be omitted. In this case, Kvasir will retain their default values.
| • Pointer type coercion | ||
| • Pointer type disambiguation example | ||
| • Using pointer type disambiguation with partial program tracing |
In addition to specifying whether a particular pointer refers to one
element or to an array of elements, the user can also specify what type
of data a pointer refers to. This type coercion acts like an explicit
type cast in C, except that it only works on struct/class types and not
on primitive types. This feature is useful for traversing inside of
data structures with generic void* pointer fields. Another use
is to cast a pointer from one that refers to a “super class” to one that
refers to a “sub class”. This structural equivalence pattern is often
found in C programs that emulate object orientation. To coerce a
pointer to a particular type, simply write the name of the struct type
after the disambiguation letter (e.g., A, P, S, C, I) in the
.disambig file:
----SECTION---- function: ..view_foo_and_bar() f P foo b P bar
Without the type coercion, Kvasir cannot print out anything except for a
hashcode for the two void* parameters of this function:
void view_foo_and_bar(void* f, void* b);
With type coercion, though, Kvasir treats f as a foo* and
b as bar* and can traverse inside of them. Of course, if
those are not the true run-time types of the variables, then Kvasir’s
output will be meaningless.
Due to the use of typedefs, there may be more than one name for a
particular struct type. The exact name that you need to write in the
.disambig file is the one that appears in that file after the
usertype prefix. Note that if a struct does not have any pointer
fields, then there will be no usertype section for it in the
.disambig file. In that case, try different names for the struct
if necessary until Kvasir accepts the name (names are all one word long;
you will never have to write struct foo). There should only be
at most a few choices to make. If the coercion if successful, Kvasir
prints out a message in the following form while it is processing the
.disambig file:
.disambig: Coerced variable f into type 'foo' .disambig: Coerced variable b into type 'bar'
One more caveat about type coercion is that you can currently only coerce pointers into types that at least one variable in the program (e.g., globals, function parameters, struct fields) belongs to. It is not enough to merely declare a struct type in your source code; you must have a variable of that type somewhere in your program. This is a limitation of the current implementation, but it should not matter most of the time because programs rarely have struct declarations with no variables that belong to that type. If you encounter this problem, you can simply create a global variable of a certain type to make type coercion work.
Next: Using pointer type disambiguation with partial program tracing, Previous: Pointer type coercion, Up: Pointer type disambiguation [Contents][Index]
This example demonstrates the power of pointer type disambiguation in creating more accurate Daikon output. Consider this file:
struct record {
char* name; // Initialize to: "Daikon User"
int numbers[5]; // Initialize to: {5, 4, 3, 2, 1}
};
void foo(struct record* bar) {
int i;
for (i = 0; i < 5; i++) {
bar->numbers[i] = (5 - i);
}
}
int main() {
char* myName = "Daikon User";
struct record baz;
baz.name = myName;
foo(&baz);
}
In foo(), bar is a pointer to a record struct. By inspection, it is
evident that in this program, bar only refers to one element: &baz
within main. However, by default, Kvasir assumes that bar is an
array of record structs since a C pointer contains no information about
how many elements it refers to. Because Kvasir must output bar as an
array and bar->numbers is an array of integers, it “flattens”
bar->numbers into 5 separate arrays named bar->numbers[0]
through bar->numbers[4]
and creates fairly verbose output. This is a direct
consequence of the fact that Daikon can only handle one layer of sequences
(it cannot handle arrays within arrays, i.e., multidimensional arrays).
Here is part of the Daikon output for this program:
====================================================================== ..foo():::ENTER bar has only one value bar[].name == [Daikon User] bar[].name elements == "Daikon User" ====================================================================== ..foo():::EXIT size(bar[]).numbers[0] == size(bar[]).numbers[0][0] size(bar[]).numbers[0] == size(bar[]).numbers[1] size(bar[]).numbers[0] == size(bar[]).numbers[1][0] size(bar[]).numbers[0] == size(bar[]).numbers[2] size(bar[]).numbers[0] == size(bar[]).numbers[2][0] size(bar[]).numbers[0] == size(bar[]).numbers[3] size(bar[]).numbers[0] == size(bar[]).numbers[3][0] size(bar[]).numbers[0] == size(bar[]).numbers[4] size(bar[]).numbers[0] == size(bar[]).numbers[4][0] bar[].name == [Daikon User] bar[].name elements == "Daikon User" bar[].numbers[0] contains no nulls and has only one value, of length 1 bar[].numbers[0] elements has only one value bar[].numbers[0][0] == [5] bar[].numbers[0][0] elements == 5 bar[].numbers[1] contains no nulls and has only one value, of length 1 bar[].numbers[1] elements has only one value bar[].numbers[1][0] == [4] bar[].numbers[1][0] elements == 4 bar[].numbers[2] contains no nulls and has only one value, of length 1 bar[].numbers[2] elements has only one value bar[].numbers[2][0] == [3] bar[].numbers[2][0] elements == 3 bar[].numbers[3] contains no nulls and has only one value, of length 1 bar[].numbers[3] elements has only one value bar[].numbers[3][0] == [2] bar[].numbers[3][0] elements == 2 bar[].numbers[4] contains no nulls and has only one value, of length 1 bar[].numbers[4] elements has only one value bar[].numbers[4][0] == [1] bar[].numbers[4][0] elements == 1 size(bar[]).numbers[0] == 1 bar[].numbers[4][0] elements == size(bar[]).numbers[0] size(bar[]).numbers[0] in bar[].numbers[4][0]
This is a bit verbose due to the fact that Kvasir treats bar like an array
by default when it actually only points to one element. However, by running
Kvasir with the --disambig option, we create the
myprog.disambig file, which we can then edit and feed back to
Kvasir to change how the pointer is treated. (We run Kvasir twice on the same
program, but we edit the .disambig file in between the runs.)
kvasir-dtrace ...options... --disambig --smart-disambig myprog
This creates the myprog.disambig file. It contains, at the top:
----SECTION---- function: ..foo() bar P
This means that at the program points corresponding to the entry and
exit of foo(), the variable bar is treated as a
‘Pointer’ type.
Since we have used the --smart-disambig option,
Kvasir automatically inferred Pointer instead of Array for bar
because it observed that bar only pointed to one element during the
execution of the target program which generated the .disambig file.
This heuristic allows users to use
.disambig files more effectively with less manual editing.
Without --smart-disambig, Kvasir does not execute the program
to make such inferences, which allows .disambig files to be generated
faster, but leaves the default disambiguation types for all entries (in
this case, bar would have the default array type of
'A').
Then, running Kvasir again with the --disambig option causes Kvasir to open the existing myprog.disambig file, read the definitions, and alter the output accordingly:
kvasir-dtrace ...options... --disambig myprog
This tells Kvasir to output bar as a ‘Pointer’ to a single
element, which in turn causes Daikon to generate a much more concise
set of invariants. Notice that bar->numbers no longer has to be
“flattened” because bar is now a pointer to one struct, so
Daikon can recognize bar->numbers as a single-dimensional
array (Daikon uses a Java-like syntax, replacing the arrow ‘->’ symbol
with a dot, so it actually outputs bar.numbers).
====================================================================== ..foo():::ENTER bar has only one value bar.name == "Daikon User" ====================================================================== ..foo():::EXIT bar.name == "Daikon User" bar.numbers has only one value bar.numbers[] == [5, 4, 3, 2, 1] size(bar.numbers[]) == 5 bar.name == orig(bar.name) size(bar.numbers[]) in bar.numbers[] size(bar.numbers[])-1 in bar.numbers[]
Previous: Pointer type disambiguation example, Up: Pointer type disambiguation [Contents][Index]
It is possible to use pointer type disambiguation while only tracing selected program points and/or variables in a target program, combining the functionality described in the Pointer type disambiguation and Tracing only part of a program sections. This section describes the interaction of the ppt-list-file, var-list-file, and .disambig files.
The interaction between selective program point tracing (via the ppt-list-file) and pointer type disambiguation is fairly straightforward: If the user creates a .disambig file while running Kvasir with a ppt-list-file that only specifies certain program points, the generated .disambig file will only contain sections for those program points (as well as the global section and sections for each struct type). If the user reads in a .disambig file while running Kvasir with a ppt-list-file, then disambiguation information is applied for all variables at the program points to be traced. This can be much faster and generate a much smaller disambiguation file, one that only contains information about the program points of interest.
The interaction between selective variable tracing (via the
var-list-file) and pointer type disambiguation is a bit more
complicated. This is because the var-list-file lists variables
as they appear in the .decls and .dtrace files, but using a .disambig
file can actually change the way that variable names are printed out in
the .decls and .dtrace files. For example, consider the test program
from the Pointer type disambiguation example. The struct
record* bar parameter of foo() is treated like an array by
default. Hence, the .decls, .dtrace, and var-list-file will list
the following variables derived from this parameter:
----SECTION---- ..foo() bar bar[].name bar[].numbers[0] bar[].numbers[0][0] bar[].numbers[1] bar[].numbers[1][0] bar[].numbers[2] bar[].numbers[2][0] bar[].numbers[3] bar[].numbers[3][0] bar[].numbers[4] bar[].numbers[4][0]
However, if we use a disambiguation file to denote bar as a
pointer to a single element, then the .decls and .dtrace files will
instead list the following variables:
----SECTION---- ..foo() bar bar->name bar->numbers bar->numbers[]
Notice how the latter variable list is more compact and reflects the
fact that bar is a pointer to a single struct. Thus, the
flattening of the numbers[5] static array member variable is no
longer necessary (it was necessary without disambiguation because Daikon
does not support nested arrays of arrays, which can occur if bar
were itself an array since numbers[5] is already an array).
Notice that, with the exception of the base variable bar, all
other variable names differ when running without and with
disambiguation. Thus, if you used a var-list-file generated on a
run without the disambiguation information while running Kvasir with the
disambiguation information, the names will not match up at all, and you
will not get the proper selective variable tracing behavior.
The suggested way to use selective variable tracing with pointer type disambiguation is as follows:
For maximum control of the output, you can use selective program point tracing, variable tracing, and disambiguation together all at once.
Next: Online execution, Previous: Pointer type disambiguation, Up: Kvasir [Contents][Index]
Kvasir supports C++, but Kvasir has been tested more on C programs than on C++ programs, so Kvasir’s C++ support is not as mature as its C support. Here is a partial list of C++ features that Kvasir currently supports:
this) to a single
instance of the class. They are printed with the class name as the
prefix, followed by a period and then the full function signature. For
example, a push() function of a Stack class might be named
Stack.push(char*).
this parameter.
this is an instance of a class that inherits from
another class called fooClass which has a member variable
fooVar, then Kvasir prints out fooVar as
this->fooClass.fooVar. This correctly handles the case of
multiple inheritance as well as several layers of inheritance. Thus,
object invariants capture properties of a class’s own member variables
as well as those of its superclasses’ member variables.
foo() will be
disambiguated by their signatures, such as foo(int, int) and
foo(double, double).
One current C++ limitation is that Kvasir cannot print out the contents
of classes which are defined in external libraries rather than in the
user’s program (e.g., it can properly output a C-string represented as
char* but not the contents of the C++ string class). If
further support for specific C++ features are important to you, please
send email to daikon-developers@googlegroups.com, so that we
can increase its priority on our to-do list.
Next: Installing Kvasir, Previous: C++ support, Up: Kvasir [Contents][Index]
The term online execution refers to running Daikon at the same time as the target program, without writing any information to a file. This can avoid some I/O overhead, prevent filling up your disk with files, and in the future Daikon may be able to produce partial results as the target program is executing. A limitation of online execution is that, unless FIFO files, or named pipes (see Online execution with DynComp for C/C++) are used, it runs Daikon over only a single execution, as opposed to generalizing over multiple executions as can be done when writing to files and supplying all the files to Daikon. The Chicory front end for Java also supports online execution, via its --daikon-online option (see Chicory miscellaneous options).
To use regular pipes in lieu of a disk file, simply use - as the
name of the .dtrace file, and run the target program and Daikon
in a Linux pipeline.
When the --dtrace-file=- option is used to redirect
the dtrace output to stdout, the target program’s stdout is redirected
to the terminal (/dev/tty) so that it does not intermix with the
dtrace output.
kvasir-dtrace --dtrace-file=- ./bzip2 --help | $DAIKON -
Of course, you could also replace --help with -vv1 file.txt to compress a text file (but start with a small one first).
(This example assumes that you have compiled the bzip2 example (in
${DAIKONDIR}/examples/c-examples/bzip2 of the distribution) by
saying gcc -gdwarf-3 -no-pie bzip2.c -o bzip2, and that
$DAIKON stands for the command that invokes Daikon, for
instance java -Xmx7g daikon.Daikon --config_option
daikon.derive.Derivation.disable_derived_variables=true.)
Instead of a regular pipe, you can use a named pipe, also known as a FIFO, which is a special kind of file supported by most Linux-compatible systems. When one process tries to open a FIFO for reading, it blocks, waiting for another process to open it for writing (or vice-versa). When both a reader and a writer are ready, the FIFO connects the reader to the writer like a regular Linux pipe.
The --output-fifo option causes Kvasir to create its output .dtrace file as a named pipe. When Kvasir is run with this option, Daikon needs to be run at the same time to read from the FIFO, such as from another terminal or using the shell’s ‘&’ operator.
For instance, the following two commands have the same effect as the pipeline above that used ordinary pipes. The FIFO is named bzip2.dtrace.
kvasir-dtrace --output-fifo ./bzip2 --help & $DAIKON bzip2.dtrace
The two commands (before and after the ampersand) could also be run in two different terminals.
| • Online execution with DynComp for C/C++ |
Up: Online execution [Contents][Index]
When running Kvasir with DynComp (the default), Kvasir generates the .decls file after it generates the .dtrace file, so it is not possible to perform online execution using one run. The recommended way to perform online execution with DynComp is to run it once and only generate a .decls file with comparability information, then run Kvasir again without DynComp and pipe the .dtrace data directly into Daikon while using the .decls file generated from the previous run:
kvasir-dtrace --decls-only ./foo
This should generate a .decls file with comparability information named daikon-output/foo.decls.
kvasir-dtrace --no-dyncomp --dtrace-no-decls --dtrace-file=- \
./foo | java -cp ${DAIKONDIR}/daikon.jar daikon.Daikon daikon-output/foo.decls -
When you run Kvasir the second time, you don’t need to run DynComp again since you are only interested in the .dtrace file. Notice that the .dtrace output is directed to standard out (--dtrace-file=-) and does not contain any declarations (--dtrace-no-decls) because the .decls file already contains the declarations. You can simply pipe that .dtrace output out to Daikon, which is invoked using the .decls file (with comparability information) generated during your previous run.
Next: Kvasir limitations, Previous: Online execution, Up: Kvasir [Contents][Index]
There are two scenarios for building the Kvasir tool:
We assume you are already familiar with the Daikon Developer Manual, in particular Compiling Daikon in Daikon Developer Manual. If that is not the case, you should read that section first.
You will need to make a clone of Fjalar’s version control repository, named fjalar, as a sibling of your Daikon clone.
cd ${DAIKONDIR}
cd ..
git clone https://github.com/codespecs/fjalar.git
You may now build Fjalar (which includes Kvasir). The following commands build Fjalar, install it locally, and make a symbolic link to it in your Daikon tree.
cd ${DAIKONDIR}
make kvasir
You may see warnings during this process. You can ignore these.
If you receive an error of the form:
readelf.c:53:17: fatal error: bfd.h: No such file or directory
#include "bfd.h"
^
compilation terminated.
then install the package binutils-dev.
If you receive an error of the form:
readelf.c:72:10: fatal error: zlib.h: No such file or directory
#include <zlib.h>
^~~~~~~~
compilation terminated.
then install the package zlib1g-dev.
Once Kvasir has been installed, it can be used via the
kvasir-dtrace script in the ${DAIKONDIR}/scripts directory. If
you have set up the Daikon environment according to the instructions
above, it should already be in your PATH. For instructions on using
Kvasir, see Kvasir.
Next: Running Kvasir on i386 binaries, Previous: Installing Kvasir, Up: Kvasir [Contents][Index]
Kvasir is based on the Valgrind dynamic program supervision framework (which is best known for its memory error detection tool). Using Valgrind allows Kvasir to interrupt your program’s execution, read its variables, and examine its memory usage, all transparently to the program. Also, rather than using your program’s source code to find the names and types of functions and variables, Kvasir obtains them from debugging information included in the executable in a standard format (DWARF).
However, Kvasir has some limitations of its own. Because Kvasir uses Valgrind, it shares Valgrind’s processor and operating system limitations. While valgrind supports many platforms, the only one currently supported by Kvasir is amd64-linux.
x86-linux refers to Intel 386-compatible processors, also variously referred to as x86, x86-32, i386, i686, IA-32, when running under a Linux kernel in 32-bit mode. amd64-linux refers to the 64-bit extension of the x86 architecture found in many newer Intel and AMD processors, also variously referred to as x86-64, IA-32e, EM64T, and Intel 64, when running under a Linux kernel in 64-bit mode. The Itanium or IA-64 architecture is not supported.
Kvasir requires that your program have debugging information available in the DWARF-2 or DWARF-3 format. (See Using Kvasir for details.) For the best results, the programs used by Kvasir should be compiled without optimization.
This subsection lists some of the known limitations of the current Kvasir release; if you encounter any problems other than listed here, please report them as bugs (see Reporting problems). The limitations are listed roughly in decreasing order of severity.
gcc.
If feasible, we recommend that you use Kvasir with version 4.7 (or newer).
Incompatibilities
between Kvasir and the debugging information produced by older gcc
versions can lead to incorrect output and, in some cases, can cause Kvasir to crash.
Previous: Kvasir limitations, Up: Kvasir [Contents][Index]
While Kvasir only works under Linux running on an x86-64 processor, modern x86-64 Linux systems can run 32-bit applications natively thanks to the x86-64 architecture’s backward compatibility, though this support is often an optional feature rather than a default.
The following steps show how to enable 32-bit support on a recent Ubuntu Linux system. Verify you are running on a x86-64 machine:
dpkg --print-architecture
This should report amd64, if not, you cannot proceed.
See if you have 32 bit support enabled:
dpkg --print-foreign-architectures
If this reports i386, skip the next step.
Otherwise, you need to add the i386 architecture:
sudo dpkg --add-architecture i386
Next you must update your package lists. This allows your system to recognize 32-bit versions of available software:
sudo apt update
Install packages necessary for 32-bit support:
sudo apt install build-essential gcc-multilib
Finally, you now need to rebuild Kvasir to generate the i386 versions of Valgrind and Kvasir.
Go to your codespecs/fjalar repository (typically cd ${DAIKONDIR}/fjalar) and run:
make very-clean make build
Next: dfepl, Previous: Kvasir, Up: Front ends and instrumentation [Contents][Index]
The Daikon front end for .NET languages, named Celeriac, is distributed separately; it currently supports the C#, F# and Visual Basic .NET languages. Celeriac runs the .NET program, creates data trace (.dtrace) files, and optionally runs Daikon on them. Celeriac is named after the celeriac plant, whose root may be used as an ingredient in soups or stews.
To use Celeriac, run your program as you normally would, but with the Celeriac Launcher. For instance, if you usually run
MyProgram.exe arg1 arg2 arg3
then instead you would run
CeleriacLauncher.exe celeriacArg1 celeriacArg2 MyProgram.exe arg1 arg2 arg3
This runs your program and creates the MyProgram.dtrace in the current directory. Since Celeriac instruments class files directly as they are loaded into .NET, you do not need to perform separate instrumentation and recompilation steps.
For more details about how to download and use Celeriac, please see https://github.com/codespecs/daikon-dot-net-front-end.
It should be noted that Celeriac works under Mono as well as under the Microsoft .NET implementation.
To insert Daikon-inferred invariants in C# source code as Code Contracts, use Scout (previously called Contract Inserter): https://bitbucket.org/michael.ernst/scout-contract-inserter/.
Next: convertcsv.pl, Previous: Celeriac, Up: Front ends and instrumentation [Contents][Index]
This section contains details about dfepl, the Daikon front end for
Perl. For a brief introduction to dfepl, see Perl examples and
Instrumenting Perl programs.
dfepl works with Perl versions 5.8 and later. (To be precise, Perl
programs instrumented with dfepl can also be run with Perl 5.6, but
the instrumentation engine, which is itself written in Perl, requires
version 5.8). dfepl reads the source code for Perl modules or
programs, and writes out instrumented versions of that code that
keep track of function parameters, and make calls to routines in the
daikon_runtime package whenever an instrumented subroutine is
entered or exited.
The instrumentation engine recognizes parameters as those variables
that are declared with my(...) or local(...) and, in the
same expression, assigned to from a value related to the argument
array @_, but only among the first contiguous series of such
assignments in the body of a subroutine. This will capture the most
common assignment idioms, such as my $self = shift; (where
shift is short for shift @_), my $x = $_[0];, and
my($x, $y, @a) = @_;, but the arguments to subroutines which
access them only directly through @_, or that perform other
operations before reading their arguments, will not be recognized.
If the uninstrumented code requested warnings via the use
warnings pragma or by adding the -w flag on the #!
line, the instrumented code will also request warnings. In this case,
or if -w is specified on the command line when running it, the
instrumented code may produce warnings that the original code did
not. There are several situations in which the instrumented code
produced by dfepl, while functionally equivalent to the original,
generates more warnings. The most common such problem, which arises
from code that captures the scalar-context return value of a
subroutine that returns a list, has been avoided in the current
version by disabling the warning in question. Other warnings which
are known to be produced innocuously in this way include
‘Ambiguous call resolved as CORE::foo(), qualify as such or use
&’ (caused by code that uses CORE:: to distinguish a built-in
function from a user subroutine of the same name), and ‘Constant
subroutine foo redefined’ (caused by loading both instrumented and
uninstrumented versions of a file). Though some such warnings
represent deficiencies in the instrumentation engine, they can be
safely ignored when they occur.
Because Perl programs do not contain static type information to distinguish, for instance, between strings and numbers, the Perl front end incorporates an additional dynamic analysis to infer these types. This type guessing, which occurs as a first pass before the program can be instrumented to produce output for Daikon, operates in a manner somewhat analogous to Daikon itself: watching the execution of a program, the runtime system chooses the most restrictive type for a variable that is not contradicted during that execution. These types indicate, for instance, whether a scalar value always holds an integer, a possibly fractional numeric value, or a reference to another object. It should not be necessary to examine or modify this type information directly, but for the curious, the syntax of the type information is described in comments in the Daikon::PerlType module.
The safest course is to infer types for variables using exactly the same program executions (e.g., test cases) which will later be used to generate traces for Daikon, as this guarantees that the type information will match the actual data written to the trace file. However, because the type-guessing-instrumented versions of programs run fairly slowly in the current version, you may be tempted to use a subset of the input data for type guessing. Doing so is possible, but it will only work correctly if the smaller tests exercise all of the instrumented subroutines and exit points with all the types of data they will later be used with. If the trace runtime tries to output a data value that doesn’t match the inferred type, the value may silently be converted according to Perl’s usual conventions (for instance, a non-numeric string may be treated as the number zero), or it may cause an error during tracing (for instance, trying to dereference a supposed array reference that isn’t). Also, if a subroutine exit point is traced but was never encountered during type guessing, the generated .decls and .dtrace files will be incompatible in a way that will cause Daikon to abort with an error message of the form ‘Program point foo():::EXIT22 appears in .dtrace file but not in any .decls file’.
Figure 7.1: Workflow of instrumenting Perl code with dfepl.
dfepl works by reading one or more Perl programs
or modules, and writing out new versions of those files, instrumented
to capture information about their execution, by default to another
directory. dfepl is used in two passes: first, before type
information is available, instrumented versions are written to a
directory daikon-untyped. These untyped programs, when run,
will write
files containing dynamically inferred type information (with the
extension .types), by default to the daikon-instrumented
directory. When dfepl is rerun with this type information, it
produces type-aware instrumented code in the
daikon-instrumented directory, which when run produces
execution traces in files with the extension .dtrace in the a
directory daikon-output.
| • dfepl options |
--absolute stores the absolute path to the output directories
(by default named daikon-untyped, daikon-instrumented or
daikon-output) in the instrumented programs, so that no matter
where the instrumented program is run, the output will go to a fixed
location. Even if these directories are given as relative paths (as is
the default), --absolute specifies that they should always be
taken as relative to the directory that was the working directory when
dfepl was run.
--no-absolute specifies the opposite, causing the output paths to be interpreted relative to the current working directory each time the instrumented program is invoked. The default, when neither option is specified, is for .types files to use an absolute path, but all others to use relative path, so that the .types files will always be in the same place as the instrumented source files that generated them, but the daikon-output directory will be created in the current directory when the program runs.
Controls the number of nested invocations of object accessor methods
to examine. For instance, suppose that the Person class has a
method mother() that returns another person (and has been
specified to dfepl as an accessor), and that $me is
an instrumented variable. If the accessor depth is 1, only
$me->mother() will be examined. If the depth is 2,
$me->mother()->mother() will also be examined. Specifying large
accessor depths is generally not advisable, especially with many
accessor methods, as the number of variables examined can be too many
for Daikon to process efficiently.
By default, the Daikon Perl trace runtime will examine at most a single level of accessors.
Look for files containing accessor lists in directory, or the
current directory if directory is omitted. For a class
Acme::Foo, accessors are methods that return information about
an object but do not modify it. dfepl cannot determine on
its own which methods are accessors, but when a list of them is
provided, it can call an object’s accessors when examining a variable
of that class to obtain more information about the object. To tell
dfepl about the accessors for Acme::Foo, make a file
listing the names of each accessor method, one per line with no other
punctuation, named Acme/Foo.accessors in the same directory as
Acme/Foo.pm.
Put generated declaration files in directory and its subdirectories. The default is daikon-output.
style should be one of combined, flat, or
tree. A style of combined specifies that the
declarations for all packages should be merged, in a file named
prog-combined.decls where prog is the name of the
program. A style of flat specifies that the declarations for
each package should be in a separate file named after the package, but
that these files should go in a single directory; for instance, the
declarations for Acme::Trampoline and
Acme::Skates::Rocket would go in files named
Acme::Trampoline.decls and Acme::Skates::Rocket.decls. A
style of tree specifies that each package should have its own
declarations file, and that those files should be arranged in
directories whose structure matches the structure of their package
names; in the example above, the files would be
Acme/Trampoline.decls and Acme/Skates/Rocket.decls.
The default is tree. Note that --decls-style and --types-style are currently constrained to be the same; if one is specified, the other will use the same value.
When --dtrace-append is specified, the instrumented program will append trace information to the appropriate .dtrace file each time it runs. When --no-dtrace-append is specified, it will overwrite the file instead.
The default behavior is to overwrite. This choice can also be
overridden, when the program is run, to always append by setting the
environment variable DTRACEAPPEND to 1.
When appending to a .dtrace file, no declaration information is ever produced, because it would be redundant to do so and Daikon does not permit re-declarations of program points.
Put generated trace files in directory and its subdirectories. The default is daikon-output.
style should be one of combined, flat, or
tree. A style of combined specifies that the traces
for all packages should be merged, in a file named
prog-combined.dtrace, where prog is the name of the
program. A style of flat specifies that the
traces for each package should be in a separate file named after the
package, but that these files should go in a single directory; for
instance, the declarations for Acme::Trampoline and
Acme::Skates::Rocket would go in files named
Acme::Trampoline.dtrace and
Acme::Skates::Rocket.dtrace. A style of tree specifies
that each package should have its own trace file, and that
those files should be arranged in directories whose structure matches
the structure of their package names; in the example above, the files
would be Acme/Trampoline.dtrace and
Acme/Skates/Rocket.dtrace.
The default is combined.
Print a short options summary.
Put instrumented source files in directory and its subdirectories. The default is daikon-untyped, or daikon-instrumented if type information is available.
Consider as many as DEPTH of the first elements of a list to be distinct entities, for the purpose of guessing their types. When subroutines return a list of values, each value may have a distinct meaning, or the list may be homogeneous. When trying to assign types to the elements of a list, the Daikon Perl trace runtime will try making separate guesses about the types of the elements of a short list, but it would be inefficient to make retain this distinction for many elements. This parameter controls how many elements of a list will be examined individually; all the others will be treated uniformly.
The default is 3.
Put all of the files that are the output of the tracing process (and therefore input to the Daikon invariant detection engine) in directory and its subdirectories. This option is a shorthand equivalent to setting both --decls-dir and --dtrace-dir to the same value.
The default behavior is as if --output-dir=daikon-output had been specified.
Use path as the location of Perl when calling the annotation
back end (a module named B::DeparseDaikon), rather than the
version of Perl under which dfepl itself is running, which
is probably the first perl that occurs on your path. For
instance, if the first version of perl on your path isn’t
version 5.8 or later, you should this option to specify another
perl program that is.
When examining nested data structures, traverse as many as num
nested references. For instance, suppose that @a is the array
@a = ({1 => [2, 3]}, {5 => [4, 2]})
If the depth is 0, then when examining @a, Daikon’s Perl trace
runtime will consider it to be an array whose elements are references,
but it won’t examine what those references point to. If the depth is
1, it will consider it to be an array of references to hashes whose
keys are integers and whose values are references, but it won’t
examine what those references point to. Finally, if the depth
is 2 or more, it will consider @a to be an array of references
to hashes whose keys are integers and whose values are references to
arrays of integers.
The default nesting depth is 3.
When referenced objects have accessor methods, or when accessors return references, the --accessor-depth and --nesting-depth options interact. Specifically, if these depths are A and R, the behavior is as if the runtime has a budget of 1 unit, which it can use either on accessors which cost 1/A or references which cost 1/R. It may thus sometimes be useful to specify fractional values for --accessor-depth and --nesting-depth; in fact, the default accessor depth is 1.5.
When --types-append is specified, the instrumented program will append type information to the appropriate .types file each time it runs. When --no-types-append is specified, it will overwrite the file instead.
The default behavior is to append. If --no-types-append is
specified, however, this choice can also be overridden, when the
program is run, to append by setting the environment variable
TYPESAPPEND to 1. There is no way to use environment variables
to force the runtime to overwrite a types file, but an equivalent
effect can be obtained by simply removing the previous types file
before each run.
Look for .types files in directory, or
daikon-instrumented if directory is omitted. When
instrumenting a module Acme::Trampoline, used in a program
coyote.pl, dfepl will look for
files named coyote-combined.types, Acme::Trampoline.types, and
Acme/Trampoline.types, corresponding to the possible choices of
--types-style. Once discovered, the files are used in the
same way as for -t.
Include type information from file when instrumenting programs or modules. Since Daikon needs to know the types of variables when they are declared, useful .decls and .dtrace files can only be produced by source code instrumented with type information. Since Perl programs don’t include this information to begin with, and it would be cumbersome to produce by hand, type information must usually be produced by running a version of the program that has itself been annotated, but without type information. The Daikon Perl trace runtime will automatically decide whether to output types, or declarations and traces, depending on whether the source was instrumented without or with types. This option may occur multiple times, to read information from multiple types files (irrelevant type information will be ignored).
Put files containing type information in directory and its subdirectories. By default, this is whatever --instr-dir is, usually daikon-instrumented.
style should be one of combined, flat, or
tree. A style of combined specifies that the types
for all packages should be merged, in a file named
prog-combined.types, where prog is the name of the
program. A style of flat specifies that the
types for each package should be in a separate file named after the
package, but that these files should go in a single directory; for
instance, the declarations for Acme::Trampoline and
Acme::Skates::Rocket would go in files named
Acme::Trampoline.types and
Acme::Skates::Rocket.types. A style of tree specifies
that each package should have its own trace file, and that
those files should be arranged in directories whose structure matches
the structure of their package names; in the example above, the files
would be Acme/Trampoline.types and
Acme/Skates/Rocket.types.
The default is tree. Note that --types-style and --decls-style are currently constrained to be the same; if one is specified, the other will use the same value.
Print additional information about what dfepl is doing,
including external commands invoked.
Next: Other front ends, Previous: dfepl, Up: Front ends and instrumentation [Contents][Index]
Daikon can process data from spreadsheets such as Excel. In order to
use such files, first save them in
comma-separated-value format,
also known as csv or comma-delimited or comma-separated-list, format.
Then, convert the .csv file into a .dtrace file (and a
.decls file) to be used by Daikon by running the
convertcsv.pl program found in the ${DAIKONDIR}/scripts
directory. For example,
convertcsv.pl myfile.csv
produces files myfile.decls and myfile.dtrace.
Important: run convertcsv.pl without any arguments in order
to see a usage message.
In order to ensure all data is processed, use Daikon with the --nohierarchy option, as follows:
java -cp ${DAIKONDIR}/daikon.jar daikon.Daikon --nohierarchy myfile.decls myfile.dtrace
In a future release, the --nohierarchy option may not be necessary, but it should always be safe to use this option.
Before running convertcsv.pl, you may need to install
Text::CSV, a Perl package that convertcsv.pl uses.
Previous: convertcsv.pl, Up: Front ends and instrumentation [Contents][Index]
It is relatively easy to create a Daikon front end for another language or run-time system. For example, people have done this without any help at all from the Daikon developers. For more information about building a new front end, see New front ends in Daikon Developer Manual.
A front end for OpenAPI, Beet, is distributed separately; see https://github.com/isa-group/Beet. Beet converts any OpenAPI specification and a collection of API requests (and responses) into input for Daikon. Beet is part of AGORA, which generates test oracles for REST APIs.
A front end for LLVM, named Udon, is distributed separately; see https://github.com/markus-kusano/udon. It can be used on any programming language that can be compiled to LLVM.
A front end for WS-BPEL process definitions, named Takuan, is distributed separately; see http://web.archive.org/web/20160528161316/https://neptuno.uca.es/redmine/projects/takuan-website.
A front end for the Eiffel programming language, named CITADEL, is distributed separately; see https://se.inf.ethz.ch/people/polikarpova/citadel/.
A front end for the Simulink/Stateflow (SLSF) programming language, named Hynger, is distributed separately; see https://github.com/verivital/hynger.
A front end for the IOA (Input/Output Automata) programming language is distributed separately; see http://groups.csail.mit.edu/tds/ioa.html.
An earlier version of Daikon included a Lisp front end, but it is no longer supported.
An earlier version of Daikon provided a source-based front end for Java
named dfej. It has been superseded by Chicory (see Chicory).
An earlier version of Daikon provided a source-based front end for C
named dfec. It has been superseded by Kvasir (binary-based, for
Linux/x86-64; see Kvasir).
Next: Troubleshooting, Previous: Front ends and instrumentation, Up: Top [Contents][Index]
This chapter describes various tools that are included with the Daikon distribution.
| • Tools for manipulating invariants | ||
| • DtraceDiff utility | ||
| • Reading dtrace files |
Next: DtraceDiff utility, Up: Tools [Contents][Index]
This section gives information about tools that manipulate invariants (in the form of .inv files).
| • Printing invariants | ||
| • MergeInvariants | ||
| • Invariant Diff | ||
| • Annotate | ||
| • AnnotateNullable | ||
| • Runtime-check instrumenter | ||
| • InvariantChecker | ||
| • LogicalCompare |
Next: MergeInvariants, Up: Tools for manipulating invariants [Contents][Index]
Daikon provides many options for controlling how invariants are printed.
Often, you may want to print the same set of invariants several
different ways. However, you only want to run Daikon once, since it may
be very time consuming. The PrintInvariants utility prints a set of
invariants from a .inv file.
PrintInvariants is invoked as follows:
java -cp ${DAIKONDIR}/daikon.jar daikon.PrintInvariants [flags] inv-file
PrintInvariants shares many flags with Daikon.
These flags are only briefly summarized here.
For more information about these flags, see Configuration options.
In particular, see the configuration options whose names start with
daikon.PrintInvariants; see General configuration options.
Print usage message.
Produce output in the given format. See Invariant syntax.
Send output to the specified file rather than stdout.
Output numbers of values and samples for invariants and program points; for debugging.
Only outputs program points that match the specified regular expression
Load the configuration settings specified in the given file. See Configuration options, for details.
Specify a single configuration setting. See Configuration options, for details.
Enable debug loggers.
Track information on specified invariant class, variables and program point. For more information, see Track logging in Daikon Developer Manual.
Print extra info about invariants, and wrap in XML tags.
This is primarily for programmatic use and for debugging.
To add just the Java class of each invariant, use
--config_option daikon.PrintInvariants.print_inv_class=true.
Next: Invariant Diff, Previous: Printing invariants, Up: Tools for manipulating invariants [Contents][Index]
The MergeInvariants utility merges multiple serialized invariant files
to create a single serialized invariant file that contains the
invariants that are true across each of the input files. The results
of merging N serialized invariant files should be the same as running
Daikon on the N original .dtrace files.
MergeInvariants is invoked as follows:
java -cp ${DAIKONDIR}/daikon.jar daikon.MergeInvariants [flags]... file1 file2...
file1 and file2 are files containing serialized invariants produced by running Daikon. At least two invariant files must be specified.
MergeInvariants shares many flags with Daikon.
These flags are only briefly summarized here.
For more information about these flags, see Daikon configuration options.
Print usage message.
Output serialized invariants to the specified file; they can later be postprocessed, compared, etc. If not specified, the results are written to standard out.
Specify a single configuration setting. See Configuration options, for details.
Enable debug loggers.
Track information on specified invariant class, variables and program point. For more information, see Track logging in Daikon Developer Manual.
Next: Annotate, Previous: MergeInvariants, Up: Tools for manipulating invariants [Contents][Index]
The invariant diff utility is designed to output the differences between two sets of invariants. Invariant diff compares invariants at program points with the same name.
Invariant diff lets you compare the invariants generated by two versions of the same program, or compare the invariants generated by different runs of one program.
Invariant diff is invoked as follows:
java -cp ${DAIKONDIR}/daikon.jar daikon.diff.Diff [flags]... file1 [file2]
file1 and file2 are files containing serialized invariants produced by running Daikon or Diff with the -o flag. If file2 is not specified, file1 is compared with the empty set of invariants.
This section describes the optional flags.
Print usage message.
Display the tree of differing invariants (default). Invariants that are the same in file1 and file2 are not printed. At least one of the invariants must be justified. Does not print “uninteresting” invariants (currently some ‘OneOf’ and ‘Bound’ invariants).
Display the tree of all invariants. Includes invariants that are the same in file1 and file2, and unjustified invariants.
Include “uninteresting” invariants in the tree of differing invariants.
Include (statistically) unjustified invariants.
Compute (file1 - file2). This is all the invariants that appear in
file1 but not file2. Unjustified invariants are treated as if they
don’t exist. Output is written as a serialized ‘InvMap’ to the file
specified with the -o option. To view the contents of the serialized
‘InvMap’, run java daikon.diff.Diff file.
Compute (file1 XOR file2).
This is all the invariants that appear in
one file but not the other. Unjustified invariants are treated as if
they don’t exist. Output is written as a serialized ‘InvMap’ to the file
specified with the -o option. To view the contents of the serialized
‘InvMap’, run java daikon.diff.Diff file.
Compute (file1 UNION file2).
This is all the invariants that appear in
either file. If the same invariant appears in both files, the one with
the better justification is chosen. Output is written as a serialized
‘InvMap’ to the file specified with the -o option. To view the contents
of the serialized ‘InvMap’, run java daikon.diff.Diff file.
Used in combination with the -m or -x option. Writes the output as a serialized ‘InvMap’ to the specified file.
Examine all program points. By default, only procedure entries and combined procedure exits are examined. This option also causes conditional program points to be examined.
Print empty program points. By default, program points are not printed if they contain no differences.
Use the specified class as a custom comparator. A custom comparator can be used for any of 3 operations: sorting the first set of invariants, sorting the second set of invariants, and combining the two sets into the pair tree. The specified class must implement the Comparator interface, and accept objects of type Invariant.
Verbose output. Invariants are printed using the repr() method, instead
of the format() method.
For internal use only. Display the statistics between two sets of invariants. The pairs of invariants are placed in bins according to the type of the invariant and the type of the difference.
For internal use only. Display the same statistics as -s, but as a tab-separated list.
For internal use only. Treat justification as a continuous value when gathering statistics. By default, justification is treated as a binary value — an invariant is either justified or it is not. For example, assume invariant ‘I1’ has a probability of .01, and ‘I2’ has a probability of .5. By default, this will be a difference of 1, since ‘I1’ is justified but ‘I2’ is not. With this option, this will be a difference of .49, the difference in the probabilities. This only applies when one invariant is justified, and the other is unjustified.
For debugging use only. Prints logging information describing the state of the program as it runs.
Next: AnnotateNullable, Previous: Invariant Diff, Up: Tools for manipulating invariants [Contents][Index]
The Annotate program inserts Daikon-generated invariants into Java source code as annotations in DBC, ESC, Java or JML format. These annotations are comments that can be automatically verified or otherwise manipulated by other tools. The Daikon website has an example of code after invariant insertion: http://plse.cs.washington.edu/daikon/StackAr.html.
Invoke Annotate like this:
java -cp ${DAIKONDIR}/daikon.jar daikon.tools.jtb.Annotate Myprog.inv Myprog.java Myprog2.java ...
The first argument is a Daikon .inv or .inv.gz file produced by running Daikon with the -o command-line argument. All subsequent arguments are .java files. The original .java files are left unmodified, but Annotate produces new versions of the .java files (with names suffixed as -escannotated, -jmlannotated, or -dbcannotated) that include the Daikon invariants as comments.
The options are:
Produce output in the given format. See Invariant syntax.
Do not use reflection to find information about the classes being instrumented. This allows Annotate to run without having access to the class files. Since the class files are necessary to generate ‘also’ tags, those tags will be left out when this option is chosen.
Output at most count invariants per program point (which ones are chosen is not specified).
Each invariant is printed using the given format (ESC, JML or DBC), but the invariant expression is wrapped inside XML tags, along with other information about the invariant.
For example, if this switch is set, the output format is ESC,
and an invariant for method foo(int x) normally prints as
/* requires x != 0; */
Then the resulting output will look something like this (all in one line; we break it up here for clarity):
/* requires <INVINFO> <INV> x != 0 </INV> <SAMPLES> 100 </SAMPLES> <DAIKON> x != 0 </DAIKON> <DAIKONCLASS> daikon.inv.unary.scalar.NonZero </DAIKONCLASS> <METHOD> foo() </METHOD> </INVINFO> ; */
Note that the comment will no longer be a legal ESC/JML/DBC comment. To make it legal again, you must replace the XML tags with the string between the ‘<INV>’ tag.
Also note the extra information printed with the invariant: the number
of samples from which the invariant was inferred, the Daikon
representation (i.e., the Daikon output format), the Java class that
the invariant corresponds to, and the method that the invariant
belongs to (null for object invariants).
If Annotate issues a warning message of the form
Warning: Annotate: Daikon knows nothing about field ...
then the Annotate tool found a variable in the source code that was computed by Daikon. This can happen if Daikon was run omitting the variable, for instance due to --std-visibility. It can also happen due to a bug in Annotate or Daikon; if that is the case, please report it to the Daikon developers.
Next: Runtime-check instrumenter, Previous: Annotate, Up: Tools for manipulating invariants [Contents][Index]
By using the AnnotateNullable program, you can insert
@Nullable annotations into your source code.
The purpose of AnnotateNullable is to make it easier to annotate
programs for the
Nullness Checker
that is part of the
Checker Framework.
As background, the Nullness Checker
warns the programmer about possible null dereference errors.
This is useful, but it requires the programmer to write a @Nullable
annotation anywhere that a variable might contain null.
(An unannotated reference is assumed to never be
null at run time.)
The AnnotateNullable tool automatically and soundly determines a subset of the
proper @Nullable annotations, reducing the programmer’s burden.
Each annotation that AnnotateNullable infers is
correct. The programmer may need to write some additional
@Nullable annotations, but that is much easier than writing them all.
To insert @Nullable annotations in your program,
follow these steps:
@Nullable annotations AnnotateNullable will produce.
java -cp ${DAIKONDIR}/daikon.jar daikon.Chicory \
--dtrace-file=an.dtrace.gz mypackage.MyClass arg1 arg2 ...
java -cp ${DAIKONDIR}/daikon.jar daikon.Daikon an.dtrace.gz --no_text_output \
--config daikondir/java/daikon/annotate_nullable.config
AnnotateNullable tool to create an annotation index file.
AnnotateNullable writes its output to standard out, so you should
redirect its output to a .jaif file.
java -cp ${DAIKONDIR}/daikon.jar daikon.AnnotateNullable an.inv.gz > nullable-annotations.jaif
# To insert in class files:
insert-annotations mypackage.MyClass nullable-annotations.jaif
# To insert in source files:
insert-annotations-to-source nullable-annotations.jaif \
mypackage/MyClass.java annotated/mypackage/MyClass.java
AnnotateNullable is invoked as follows:
java -cp ${DAIKONDIR}/daikon.jar daikon.AnnotateNullable [flags] inv-file
The flags are:
Adds ‘NonNull’ annotations as well as ‘Nullable’ annotations. Unlike ‘Nullable’ annotations, ‘NonNull’ annotations are not guaranteed to be correct.
Next: InvariantChecker, Previous: AnnotateNullable, Up: Tools for manipulating invariants [Contents][Index]
The runtimechecker instrumenter inserts, into a Java file, instrumentation code that checks invariants as the program executes. For a full list of options, run:
java -cp ${DAIKONDIR}/daikon.jar daikon.tools.runtimechecker.Main help
The instrument command to runtimechecker creates a new directory
instrumented-classes containing a new version of the
user-specified Java files, instrumented to check invariants at run time
and to record a list of invariant violations in a Java data structure.
You can compile and run the instrumented version of your program.
Here is an example of using the runtime-check instrumenter to create a version of file ubs/BoundedStack.java that checks the invariants in invariant file BoundedStack.inv.gz:
java daikon.tools.runtimechecker.Main instrument BoundedStack.inv.gz \
ubs/BoundedStack.java
The instrumented Java code references classes in the
daikon.tools.runtimechecker package, so those classes must be
present in the classpath when the instrumented classes are compiled and
executed.
Invariants are evaluated at the program points at which they should hold. Three things can happen when evaluating an invariant:
daikon.tools.runtimechecker.Property is added to a list in the
class daikon.tools.runtimechecker.Runtime. A programmer can
obtain the growing list of violated invariants through the method
daikon.tools.runtimechecker.Runtime.getViolations(). (See
that class for other useful methods.)
Throwable (exception) is thrown when evaluating the
invariant. In this case, the throwable is added to the list
daikon.tools.runtimechecker.Runtime.internalInvariantEvaluationErrors.
The throwable is not rethrown.
Note that the instrumented program does not do anything with the list of violations; it merely creates the list. You will need to write your own code to process that list; see How to access violations.
| • How to access violations | ||
| • Problems compiling instrumented code |
The instrumented class handles violations silently:
it simply adds them to a list in the class
daikon.tools.runtimechecker.Runtime.
No “invariant violation” exceptions are thrown, and the violated
invariants can only be obtained dynamically (while the program is running)
by calling daikon.tools.runtimechecker.Runtime.getViolations().
To obtain a file of all the violations for a program execution, you can use
program daikon.tools.runtimechecker.WriteViolationFile.
For example, if you usually run
java MyProg arg1 arg2
then instead you would run
java -cp myclasspath:${DAIKONDIR}/daikon.jar daikon.tools.runtimechecker.WriteViolationFile MyProg arg1 arg2
This will create a file called violations.txt in the
current directory, immediately before the program exits normally.
If the program under test calls System.exit, then no
violations.txt file is created. (JUnit is an example of a program
that calls System.exit.)
The following code snippet contains a method callMethod() which
presumably calls one of the methods in the instrumented class.
The code detects if any violations occurred, and if so, prints
a message.
daikon.tools.runtimechecker.Runtime.resetViolations();
daikon.tools.runtimechecker.Runtime.resetErrors();
callMethod();
List<Violation> vs = daikon.tools.runtimechecker.Runtime.getViolations();
if (!vs.isEmpty())
System.out.println("Violations occurred.");
In addition, the instrumenter adds the following two methods to the instrumented class:
isDaikonInstrumented(). Returns true (you could calling
this method to see if the class has been instrumented).
getDaikonInvariants(). Returns the array of properties being checked.
Previous: How to access violations, Up: Runtime-check instrumenter [Contents][Index]
When compiling the instrumented code, the Java compiler might emit an error such as:
error: longitude has private access in GeoPoint
If you receive the error above, then a variable in an invariant
(longitude in this case) has been declared private.
There are two ways to fix this. To check invariants that mention private variables, supply the --make_all_fields_public command-line option when running ‘java daikon.tools.runtimechecker.Main instrument ...’. To ignore invariants that mention private variables, rebuild the .dtrace file by rerunning Chicory using the --std-visibility command-line option.
Another error the Java compiler might emit is:
error: code too large for try statement
You get the above error if the combined size of the original source code, plus the instrumentation code, is larger than the JVM’s limit of 65536 bytes of bytecode per method.
You can correct the problem by using a smaller number of invariants when instrumenting. See Too much output.
(Eventually, it might be nice for the instrumenter to place its code in one or more separate methods so that no one of them is too large.)
Next: LogicalCompare, Previous: Runtime-check instrumenter, Up: Tools for manipulating invariants [Contents][Index]
The InvariantChecker program takes a set of invariants found by Daikon
and a set of data trace files. It checks each sample in the data trace
files against each of the invariants. Any sample that violates an invariant
is noted, via a message printed to standard output or to a specified
output file.
InvariantChecker is invoked as follows:
java -cp ${DAIKONDIR}/daikon.jar daikon.tools.InvariantChecker [options] invariant-file dtrace-files
The invariant-files are invariant files (.inv) created by running Daikon. The dtrace-files are data trace (.dtrace) files created by running the instrumented program. The files may appear in any order; the file type is determined by whether the file name contains .dtrace, or .inv.
The options are:
Print usage message.
Write any violations to the specified file.
Checks only invariants that are above the default confidence level.
Checks only invariants that are not filtered by the default filters.
Print all samples that violate an invariant. By default only the totals are printed.
Processes all invariant files in the given directory and reports the number of invariants that failed on any of the .dtrace files in that directory. We only process invariants above the default confidence level and invariants that have not been filtered out by the default filters.
These switches are the same as for Daikon. They are described in Running Daikon.
Previous: InvariantChecker, Up: Tools for manipulating invariants [Contents][Index]
Suppose you have two sets of invariants describing the operation of a software
module or describing two implementations of a module with the same
interface. Roughly, one set of invariants is “stronger” than
another if in any situation where the “stronger” invariants
hold, the “weaker” invariants also hold. The LogicalCompare tool
checks whether two sets of invariants satisfy this relationship.
In order to use LogicalCompare, Simplify must be installed
(see Installing Simplify).
An invocation of LogicalCompare has the following form:
java -cp ${DAIKONDIR}/daikon.jar daikon.tools.compare.LogicalCompare [options] \
weak-invs strong-invs [enter-ppt [exit-ppt]]
The LogicalCompare program takes two mandatory arguments, which are
.inv files containing invariants. LogicalCompare
checks whether the invariants in the first file are weaker
(implied by) the invariants in the second file.
LogicalCompare prints any exceptions to this implication,
preceded by the text “Invalid:”.
To be precise, for each
pair of program points representing a single method or function,
LogicalCompare will check that each precondition (:::ENTER point
invariant) in the “stronger” invariant set is implied by some
combination of invariants in the “weaker” invariant set, and that
each postcondition (:::EXIT point invariant) in the “weaker” invariant
set is implied by some combination of postconditions in the
“stronger” set and preconditions in the “weaker” set.
If no other regular arguments besides the two .inv files are supplied,
all the method or function program points that exist in both files
will be compared, with a exception message reported for each method
that exists in the “weaker” set but not the “stronger”.
Alternatively, one or two additional arguments may be supplied, which name an
:::ENTER program point and an :::EXIT program point to examine
(if only an :::ENTER program point is supplied,
the corresponding combined :::EXIT point
is selected automatically).
LogicalCompare accepts the following options:
Read additional assumptions about the behavior of compared routines
from the file file. The assumptions file should consist of lines
starting with ‘PPT_NAME’, followed by the complete name of an
:::ENTER program point, followed by lines each consisting of a Simplify
formula, optionally followed by a # and a human-readable
annotation. Blank lines and lines beginning with a # are
ignored. The assumption properties will be used as if they were
invariants true at the strong :::EXIT point when checking
weak :::EXIT point invariants.
Specify a single configuration setting. The available settings are the same as can be passed to Daikon’s --config_option option, though because the invariants have already been generated, some will have no effect. For a list of available options, see Configuration options.
Read configuration options from the file file. This file should have the same format as one passed to Daikon’s --config option, though because the invariants have already been generated, some will have no effect.
These options have the same effect as the --debug and --dbg options to Daikon, causing debugging logs to be printed.
Control which invariants are removed from consideration before
implications are checked. Note that except as controlled by this
option, LogicalCompare does not perform any of the filters that
normally control whether invariants are printed by Daikon. Also,
invariants that cannot be formatted for the Simplify automatic theorem
prover will be discarded in any case, as there would be no other way
to process them. Each letter controls a filter: an invariant is rejected
if it is rejected by any filter (or, equivalently, kept only if it
passes through every filter).
Discard upper-bound and lower-bound invariants (such as ‘x <= c’ and ‘x >= c’ for a constant c), when Daikon considers the constant to be uninteresting. Currently, Daikon has a configurable range of interesting constant: by default, -1, 0, 1, and 2 are interesting, and no other numbers are.
Discard all bound invariants, whether or not the constants in them are considered interesting.
Discard ‘one-of’ invariants (which signify that a variable always had one of a small set of values at run time), when the values that the variable took are considered uninteresting by Daikon.
Discard all ‘one-of’ invariants, whether or not the values involved are interesting.
Discard invariants for which it was never the case that all the variables involved in the invariant were present at the same time.
Discard invariants that Daikon determines to be statistically unjustified, according to its tests.
Discard invariants that refer to the values of pass-by-value parameters in the postcondition, or to the values of objects pointed to by parameters in postconditions, when the pointer is not necessarily the same as at the entrance to the method or function. Usually such invariants reflect implementation details that would not be visible to the caller of a method.
Discard implication invariants when they appear in :::ENTER program
points.
The default set of filters corresponds to the letters ijmp.
Print a brief summary of available command-line options.
If implication is not verified between two invariant sets after examining the preconditions, do not continue to check the implication involving postconditions. Because the postconditions aren’t formally meaningful outside the domain specified by the preconditions, this is the safest behavior, but in practice trivial precondition mismatches may prevent an otherwise meaningful postcondition comparison. See also --post-after-pre-failure.
For each implication among invariants that is verified, print a minimal set of conditions that establish the truth of the conclusion. The set is minimal, in the sense that if any condition were removed, the conclusion would no longer logically follow according to Simplify, but it is not the least such set: there may exist a smaller set of conditions that establish the conclusion, if that set is not a subset of the set printed. Beware that because this option uses a naive search technique, it may significantly slow down output.
Even if implication is not verified between two invariant sets after examining the preconditions, continue to check the implication involving postconditions. This is somewhat dangerous, in that if the implication does not hold between the preconditions, the invariant sets may be inconsistent, in which case reasoning about the postconditions is formally nonsensical, but the tool will attempt to ignore the contradiction and carry on in this case. This is now the default behavior, so the option has no effect, but it is retained for backward compatibility. See also --no-post-after-pre-failure.
Print a count of the number of invariants checked for implication.
For each invariant, show how it is represented as a logical formula passed to Simplify.
Rather than testing implications among invariants, simply print the
sets of weak and strong :::ENTER and :::EXIT point invariants that would
normally be compared. The invariants are selected and filtered as
implied by other options.
Print invariants that are verified to be implied (“valid”), as well as those for which the implication could not be verified (“invalid” invariants, which are always printed).
For each set of invariants checked, print the total time required for
the check. This time includes both processing done by LogicalCompare
directly, and time spent waiting for processing done by Simplify, but
does not include time spent deserializing the .inv input
files.
Next: Reading dtrace files, Previous: Tools for manipulating invariants, Up: Tools [Contents][Index]
DtraceDiff is a utility for comparing data trace (.dtrace) files.
It checks that the same program points are visited in the same order in
both files, and that the number, names, types, and values of variables
at each program point are the same. The differences are found using a
content-based, rather than text-based, comparison of the two files.
DtraceDiff stops by signaling an error when it finds a difference
between the two data trace files. (Once execution paths have
diverged, continuing to emit record-by-record differences is likely to
produce output that is far too voluminous to be useful.) It also
signals an error when it detects incompatible program point
declarations or when one file is shorter than the other.
DtraceDiff is invoked as follows:
java -cp ${DAIKONDIR}/daikon.jar daikon.tools.DtraceDiff [flags] \
[declsfiles1] dtracefile1 [declsfiles2] dtracefile2
Corresponding declarations (.decls) files can optionally be
specified on the command line before each of the two .dtrace
files. Multiple .decls files can be specified. If no
.decls file is specified, DtraceDiff assumes that the
declarations are included in the .dtrace file instead.
DtraceDiff supports the following Daikon command-line flags:
Print usage message.
Load the configuration settings specified in the given file. See Configuration options, for details.
Specify a single configuration setting. See Configuration options, for details.
Only process program points whose names match the regular expression.
Do not process program points whose names match the regular expression. This takes priority over the --ppt-select-pattern argument.
Only process variables (whether in the trace file or derived) whose names match the regular expression.
Ignore variables (whether in the trace file or derived) whose names match the regular expression, which uses Perl syntax. This takes priority over the --var-select-pattern argument.
DtraceDiff uses appropriate comparisons for the type of the variables in
each program point being compared. In particular:
Previous: DtraceDiff utility, Up: Tools [Contents][Index]
If you wish to write a program that manipulates .dtrace files, then see See Reading dtrace files in Daikon Developer Manual.
This chapter gives solutions for certain problems you might have with Daikon. It also tells you how to report bugs in a useful manner.
If, after reading this section and other parts of the manual, you are unable to solve your problem, you may wish to send mail to one of the mailing lists (see Mailing lists).
| • Daikon problems | ||
| • Large dtrace files | ||
| • Chicory problems | ||
| • Reporting problems | ||
| • Further reading |
Next: Large dtrace files, Up: Troubleshooting [Contents][Index]
You may find the debugging flags --debug and --dbg category useful if you wish to track down bugs or better understand Daikon’s operation; see Daikon debugging options. See Configuration options, for another way to adjust Daikon’s output.
Next: File input errors, Up: Daikon problems [Contents][Index]
Either of these errors:
Error: Could not find or load main class daikon.Chicory Exception in thread "main" java.lang.NoClassDefFoundError: daikon/Chicory
means that you have not put daikon.jar on the classpath.
More generally, an error such as one of these:
Error: Could not find or load main class mypackage.MyClass Exception in thread "main" java.lang.NoClassDefFoundError: mypackage/MyClass
means that Java did not find the class mypackage.MyClass on the classpath. To correct the problem, you need to make sure that the directory or jar file that contains file mypackage/MyClass.class is on your classpath. The classpath is passed as a command-line argument such as -cp or -classpath.
When investigating such a problem, you should verify that you can run your
program when not using Daikon; for example, if you are trying to run
java -cp myclasspath:${DAIKONDIR}/daikon.jar daikon.Chicory mypackage.MyClass arg1 arg2 arg3, then make
sure that the identical command without daikon.Chicory works, in
this case java -cp myclasspath:${DAIKONDIR}/daikon.jar mypackage.MyClass arg1 arg2 arg3. If
both commands issue the same error, then the problem is unrelated to Daikon.
If the two commands behave differently, that is a bug in Daikon.
Next: decl format errors, Previous: Can't run Daikon, Up: Daikon problems [Contents][Index]
If Daikon terminates with an error such as
Error at line 530 in file test.dtrace
and inspection of the indicated file at the indicated line number does not help you to discern what is wrong, you may wish to re-run Daikon with the show_stack_trace option. The exact syntax for this is:
--config_option daikon.Debug.show_stack_trace=true
The additional information in the resulting exception stack trace should indicate where the problem is occurring.
Next: Too much output, Previous: File input errors, Up: Daikon problems [Contents][Index]
If Daikon terminates with an error such as
decl format '2.0' does not match previous setting at line 4 in file test.dtrace
it means you are using multiple .dtrace and/or .decls files and they are not all in the same format. (See Declaration version in Daikon Developer Manual for information about how to determine a data file’s format.)
The most probable cause is you are using at least one version 1 .decls file or .dtrace file generated by an older version of Chicory/DynComp and at least one current .decls file or .dtrace file (which defaults to version 2) as input to Daikon. (Note that the C/C++ front end Kvasir generates a version 2 file .decls.) The way to avoid this problem is to use your Java-DynComp-generated .decls files as input to Chicory. The resulting .dtrace file will contain the comparability values from the .decls file(s) and can then be used as input to Daikon. Passing a .decls file to Chicory is described in Detecting invariants in Java programs, for example:
java -cp ${DAIKONDIR}/daikon.jar daikon.Chicory \
--comparability-file=MyClass.decls-DynComp \
mypackage.MyClass arg1 arg2 arg3
Next: Missing output invariants, Previous: decl format errors, Up: Daikon problems [Contents][Index]
Sometimes, Daikon may produce a very large number of seemingly irrelevant properties that obscure the facts that you were hoping to see. Which properties are irrelevant depends on your current task, so Daikon provides ways for you to customize its output. See Daikon’s command-line options (see Running Daikon), and the techniques for enhancing its output (see Enhancing Daikon output), including its configuration options (see Configuration options). The options for the front ends — such as DynComp (see DynComp for Java options), Chicory (see Chicory options) and Kvasir (see Kvasir options) — give additional control.
Some irrelevant properties are over unrelated variables, like comparing an array index to elements of the array. You should always use the DynComp tool (see DynComp for Java, DynComp for C/C++) to avoid producing such properties.
Some irrelevant properties are not relevant to the domain (e.g., bitwise operations). You can exclude whole classes of unhelpful invariants from Daikon’s output (see Options to enable/disable specific invariants).
Some irrelevant properties are over variables you do not care about, or are in parts of the program that you do not care about. You can exclude certain variables or procedures from Daikon’s output (see Processing only part of the trace file and Options to enable/disable derived variables).
Some irrelevant properties are logically redundant — multiple properties express the same facts in different ways. You can eliminate such properties from Daikon’s output (see Options to control invariant detection).
Some irrelevant output indicates a deficiency in your test suite: your test suite is so small that many arbitrary properties hold over it. This happens when the test suite does not execute the code with a broad distribution of values, but only executes the code with a few specific values. This problem disappears if you augment your test suite so that it exercises the code with more different values.
More generally, each property that Daikon produces is a true fact about how the target program behaved. However, some of these facts would be true for any execution of the target program, and others are accidents of the particular executions that Daikon observed. Both types of facts may be useful, but for different reasons: the former tell you about your program, and the latter tell you about your test suite (and how to improve it!).
Next: True invariants are not reported due to output filters, Previous: Too much output, Up: Daikon problems [Contents][Index]
Daikon may sometimes fail to output invariants that you expect it to output. Here are some reasons why this may happen:
There are two command-line options (--disc_reason and --track) that will display information about invariants that are not printed. The --disc_reason option will indicate why a particular invariant was discarded in most cases. If it does not provide enough information, try the --track option which traces the invariant through all of Daikon’s processing steps. See Daikon debugging options for more information.
Note that in each case the description (class, variables, program point) of the invariant must be entered carefully. It may be helpful to try the option on a similar invariant that is printed to make sure that each is specified correctly.
Next: No samples, Previous: Missing output invariants, Up: Daikon problems [Contents][Index]
Sometimes, Daikon does not report an invariant, even though Daikon has computed that the invariant is true throughout the sample data. Daikon only reports invariants that satisfy all the output filters (see Invariant filters).
Here, we discuss two common reasons for filtering: statistical justification, and implication.
Daikon only reports a property if it is statistically justified, and Daikon needs to see enough samples for the statistical test to work. So, there may be a property that is true, but if too few samples were seen, then Daikon will not report it. In a longer trace, Daikon would report the property. You can adjust Daikon’s confidence limit so that the property is reported even in the short executions; see the command-line option --conf_limit. For instance, supplying --conf_limit 0 causes all properties that have not been falsified to be printed.
Daikon does not report redundant, or implied, invariants (see Redundant invariants). The purpose of this is to avoid cluttering the output with facts that add no new information. Here are a few examples:
i < j and
i <= j are true. Daikon would report
only i < j; Daikon would not report i <= j, which is
implied by what Daikon has reported. Further suppose that a longer
execution had a sample containing i=22, j=22. Only i <= j
would be true in the second execution, and Daikon would report it.
(The invariant i < j is an example of a false positive or
overfitting in the first execution.)
Next: No return from procedure, Previous: True invariants are not reported due to output filters, Up: Daikon problems [Contents][Index]
When Daikon produces no output, that is usually a result of it having no samples from which to generalize. Use the --output_num_samples flag to Daikon to find out how many samples it is observing. This section tells you how to debug your problem if the answer is 0, but you believe that there are samples in the file you are feeding to Daikon.
Using the normal dataflow hierarchy, Daikon explicitly processes
:::EXIT program points only. Other program points, such as
:::ENTER program points, are processed indirectly when their
corresponding :::EXIT points are encountered.
(You can disable this behavior with the
--nohierarchy switch to Daikon;
see Options to control invariant detection.)
If no :::EXIT program points are present (perhaps every
execution threw an exception, you filtered out all the
:::EXIT program points, or the data trace is obtained from
spreadsheet data instead of from a program execution),
then Daikon will not process any of the other program points, such as
the :::ENTER program points. You can make Daikon print information
about unmatched procedure entries
via the ‘daikon.FileIO.unmatched_procedure_entries_quiet’
configuration option (see General configuration options).
Another way to increase the number of invariants printed out is to lower the confidence bound cutoff. Daikon only prints invariants whose confidence level is greater than the bound specified by the --conf_limit option (see Options to control invariant detection). In order to maximize the number of invariants printed, use --conf_limit 0 to see all invariants Daikon is considering printing.
To try to determine why an invariant is not printed, use the --track to determine why Daikon does not print an invariant (see Daikon debugging options).
Next: Unsupported class version, Previous: No samples, Up: Daikon problems [Contents][Index]
Daikon sometimes issues a warning that a procedure in the target program was entered but never exited (that is, the target program abnormally terminated). In other words, the .dtrace file contains more entry records than exit records for the given procedure. Some procedures that were entered were never recorded to have exited: either they threw an exception, skipping the instrumentation code that would have recorded normal termination, or the target program’s run was interrupted. When this happens, the entry sample is ignored; the rationale is that the particular values seen led to exception exit, were probably illegal, and so should not be factored into the method preconditions.
In some cases, exceptional exit from a procedure can cause procedure
entries and exits (in the trace file) to be incorrectly matched up; if
they are incorrectly matched, then the orig(x) values may
be incorrect. Daikon has two techniques for associate procedure exits
with entries — the nonce technique and the stack technique. If a
.dtrace file uses the nonce technique, orig(x)
values are guaranteed to be correct. If a .dtrace file uses
the stack technique, then incorrect orig(x) values are
likely to occur. You can tell which technique Daikon will use by
examining the .dtrace file. If the second line of each entry
in the .dtrace file is ‘this_invocation_nonce’, then Daikon
uses the nonce technique. Otherwise, it uses the stack technique.
Which technique is used is determined by the front end, which creates
the .dtrace file, and typically cannot be controlled by the
user.
Next: Out of memory, Previous: No return from procedure, Up: Daikon problems [Contents][Index]
Daikon requires a Java 8 (or newer) JVM (see Requirements). An error such as
Exception in thread "main" java.lang.UnsupportedClassVersionError: daikon/Daikon (Unsupported major.minor version 52.0)
indicates that you are trying to run Daikon on an older JVM. You need to install a newer version of Java in order to run Daikon.
Next: Simplify errors, Previous: Unsupported class version, Up: Daikon problems [Contents][Index]
If Daikon runs out of memory, generating a message like
Exception in thread "main" java.lang.OutOfMemoryError
<<no stack trace available>>
then it is likely that it has created more invariants than will fit
in memory. The number of invariants created depends on the number of
program points and the number of variables at each program point.
In addition to the solutions discussed in Reducing program points,
you can try increasing the amount of memory available to Java
with the -Xmx argument to java. (This flag is
JVM-specific; see your JVM documentation for details. For instance,
its name in JDK versions 1.2 and earlier is -mx.)
However, the value you use should be less than your system’s total amount
of physical memory.
Some implementations of Java use a surprisingly small default, such as 64
megabytes; to permit use of up to 2048
megabytes, you would run Java like so:
java -Xmx7g ...
though you can use much more depending on the limitations of your JVM.
If you are using Chicory’s --daikon command-line argument to run Daikon, then you must separately indicate the amount of memory available to Chicory and to Daikon (the latter with Chicory’s --heap-size command-line argument). For example:
java -Xmx7g daikon.Chicory --comparability-file=MyClass.decls-DynComp \
--heap-size=7g --daikon mypackage.MyClass arg1 arg2 arg3
When using the Java HotSpot JVM, an additional parameter may need to
be increased. HotSpot uses a separately-limited memory region, called
the permanent generation, for several special kinds of allocation,
one of which (interned strings) Daikon sometimes uses heavily. It may
be necessary to increase this limit as well, with the
-XX:MaxPermSize= option. For instance, to use 512 megabytes,
of which at most 256 can be used for the permanent generation, you
would run Java like so:
java -Xmx7g -XX:MaxPermSize=256m
Another possible problem is the creation of too many derived variables. If you supply the --output_num_samples option to Daikon (see Options to control Daikon output), then it will list all variables at each program point. If some of these are of no interest, you may wish to suppress their creation. For information on how to do that, see Options to enable/disable derived variables. Also see Reducing variables for other techniques.
Any output generated before the out-of-memory error is perfectly valid.
Next: Contradictory invariants, Previous: Out of memory, Up: Daikon problems [Contents][Index]
The warning ‘Could not utilize Simplify’ and/or ‘Couldn't start Simplify’ indicates that the Simplify theorem-prover could not be run; this usually indicates that the Simplify binary was not found on the user’s path.
If Simplify is not used, certain redundant (logically implied) invariants may appear in Daikon’s output. The output is correct, but more verbose than it would be if you used Simplify.
| • Installing Simplify |
Up: Simplify errors [Contents][Index]
Obtain Simplify from https://web.archive.org/web/20170201034825/https://www.kindsoftware.com/products/opensource/archives/Simplify-1.5.5-13-06-07-binary.zip, and unzip the zip file.
Either place the appropriate binary on your path, named Simplify,
or set set the simplify.path property to its absolute pathname.
Note: Older versions of the Z3 theorem
prover (https://github.com/Z3Prover/z3)
can replace Simplify, but more recent versions do not support the Simplify
syntax. In the future, it would be nice to rewrite Daikon’s theorem-prover
interface to use the SMT-LIB2 language, so that a compatible
solver like Z3 or CVC4 could be used.
The main challenge to this is writing the
boilerplate code to output each different kind of invariant in
SMT-LIB2 format.
Next: Method needs to be implemented, Previous: Simplify errors, Up: Daikon problems [Contents][Index]
The invariants Daikon produces are all true statements about the supplied program executions, so they should be mutually consistent. Sometimes, however, because of a bug or a limitation in Daikon, contradictory invariants are produced.
One known problem involves object invariants. Daikon infers object invariants by observing the state of an object when its public methods are called. However, if an object has publicly accessible fields that are changed by code outside the class, after which no public methods are called, invariants about the state of the object as seen by other code can contradict the class’s object invariants. A workaround is to allow changes to an object’s state from outside the class only by way of public methods.
Besides confusing the user, contradictory invariants also cause trouble for the Simplify theorem prover that implements the --suppress_redundant option. When the invariants at a particular program point contradict each other or background information (such as the types of objects), Simplify becomes unable to distinguish redundant invariants from non-redundant ones.
The best solution in such cases is to fix the underlying cause of the contradictory invariants, but since that is sometimes not possible, Daikon will try to work around the problem by avoiding the invariants that cause a contradiction. Daikon will attempt to find a small subset of the invariants that aren’t mutually consistent, and remove one, repeating this process until the remaining invariants are consistent. (Note that the invariants are removed only for the purposes of processing by Simplify; this does not affect whether they will be printed in the final output). While this technique can allow redundant invariants to be found when they otherwise wouldn’t be, it has some drawbacks: the choice of which invariant to remove is somewhat arbitrary, and the process of finding contradictory subsets can be time consuming. The removal process can be disabled with the daikon.simplify.LemmaStack.remove_contradictions configuration option.
Next: Daikon runs slowly, Previous: Contradictory invariants, Up: Daikon problems [Contents][Index]
Daikon may produce output like the following (but all on one line):
method daikon.inv.binary.twoSequence.SubSequence.format_esc() needs to be implemented: this.theArray[0..this.topOfStack] is a subsequence of orig(this.theArray[0..this.topOfStack])
This indicates that a particular invariant (shown on the last two lines above) cannot be formatted using the current formatting. In this example, the invariant can be formatted using Daikon’s default formatting (which is how it is shown above), but (as of April 2002) Daikon cannot output it in ESC format, so Daikon prints the above message instead. The message also shows exactly what Java method needs to be implemented to correct the problem. You can ignore such messages, or else use an output formatting that can handle those invariants. Annotate (see Annotate) automatically ignores unformattable invariants.
Next: Bigger traces cause invariants to appear, Previous: Method needs to be implemented, Up: Daikon problems [Contents][Index]
If Daikon runs slowly, there are three general possible reasons:
To understand which part is the bottleneck, you might want to separate the creation and analysis of the trace file, so you can compare the time of each part. The next two sections address each of these issues.
You may find command-line arguments like the following useful when debugging Daikon’s performance:
--config_option daikon.Daikon.progress_delay=100 --show_progress --dbg daikon.init
For additional details on improving Daikon’s performance, see Out of memory.
Creating a trace can take a long time, because of the time to traverse and print the values of many variables. Reducing the number of program points or variables can speed up both creation and analysis of trace files. For instance, you might configure your front end to skip certain procedures (helper procedures, libraries) or not to output certain variables (large arrays or static variables), or you might split a trace file into multiple parts and process them separately. For details, see Large dtrace files.
Daikon’s run time and space depend on the particular data that it analyzes. Informally, invariant detection time can be characterized as
O((vars^3 * falsetime + trueinvs * testsuite) * procedures)
where vars is the number of variables at a program point, falsetime is the (small constant) time to falsify a potential invariant, trueinvs is the (small) number of true invariants at a program point, testsuite is the size of the test suite, and procedures is the number of instrumented program points. The first two products multiply a number of invariants by the time to test each invariant.
If there are many true invariants over an input, then Daikon continues to check them all over the entire input. By contrast, if not many invariants are true, then Daikon need no longer check them once they are falsified (which in practice happens quickly). Daikon processes each procedure independently.
Another important factor affecting Daikon’s run time is the number of
variables. Because invariants involve up to three variables each, the
number of invariants to check is cubic in the number of variables at a
single program point. Derived variables (such as a[i],
introduced whenever there is both an array a and an integer
i) can increase the number of variables substantially.
The daikon.derive.Derivation.disable_derived_variables and individual
daikon.derive.*.*.enabled configuration variables
(see Options to enable/disable derived variables) may be used
to disable derived variables altogether or selectively, at the cost of
detecting fewer invariants, especially over sequences.
As noted earlier, using a comparability analysis (see Dynamic abstract type inference (DynComp)) also reduces the number of invariants that Daikon checks, and thereby speeds up Daikon.
Previous: Daikon runs slowly, Up: Daikon problems [Contents][Index]
Suppose that you run Daikon twice. The first time, you supply Daikon with traces T. The second time, you supply Daikon with more traces T+T’ for the same program points. The second Daikon execution may report the same invariants, fewer invariants, more invariants, or a mix.
The second execution may report the same invariants if the additional samples in T’ do not add any more information than those in T,
The second execution may report fewer invariants, because the additional data has eliminated overfitting (false positives). There may have been some accidental property of the shorter executions that is not true in the longer ones.
The second execution may report more invariants, because the first execution did not report some invariants that were true. True invariants are not reported due to output filters describes reasons that Daikon might not report this invariants that are true — for example, because they were not statistically justified.
Another reason that the second execution might report more invariants is if T+T’ contains samples for program points that were not in T. The first execution will not report any facts about program points that were not executed.
Next: Chicory problems, Previous: Daikon problems, Up: Troubleshooting [Contents][Index]
Running instrumented code can create very large .dtrace files. This can be a problem because writing the large files can slow the target programs substantially, or because the large files may fill up your disk.
This section describes ways to work around this problem.
| • Compression | ||
| • Scratch directory | ||
| • Run Daikon online | ||
| • Multiple smaller files | ||
| • Less information per file |
Next: Scratch directory, Up: Large dtrace files [Contents][Index]
You can reduce file size by specifying a trace file name that includes
.gz at the end. See the --dtrace-file=FILENAME argument
to Chicory or Kvasir, or the DTRACEFILE environment variable.
(Compression is the default if you don’t specify a filename.)
Next: Run Daikon online, Previous: Compression, Up: Large dtrace files [Contents][Index]
Sometimes, the problem is just filling up your user account with large files. You can instead create .dtrace files in a temporary directory. Under Linux, this is often called /scratch. Typically you should create a subdirectory called /scratch/$USER/.
Next: Multiple smaller files, Previous: Scratch directory, Up: Large dtrace files [Contents][Index]
The term online execution refers to running Daikon at the same time as the target program. The front end supplies information to Daikon directly over a socket or pipe, without writing any information to a file. This can avoid some I/O overhead, and it prevents filling up your disk with files.
The Chicory front end supports online execution via use of the --daikon-online option (see Chicory miscellaneous options). The Kvasir front end supports online execution via use of (normal or named) Linux pipes (see Online execution).
In the future, Daikon may be able to output partial results as the target program is executing.
Next: Less information per file, Previous: Run Daikon online, Up: Large dtrace files [Contents][Index]
It is usually possible to create an .inv file equivalent to
the one that Daikon would have computed, had Daikon been able to
process your entire program over its full test suite. First, use the
techniques below (see Reducing program points) to split your
.dtrace file into parts. Next, run Daikon on each resulting
.dtrace file. Finally, use the MergeInvariants tool
(see MergeInvariants) to combine the resulting .inv files into
one.
Previous: Multiple smaller files, Up: Large dtrace files [Contents][Index]
You can record less information from each program execution, or you can make Daikon read less information from the trace files. It’s usually most efficient to do the pruning as early in the process as possible. For example, it is better to have the front end output less information, rather than have Daikon ignore some of the information.
| • Reducing program points | ||
| • Reducing variables | ||
| • Reducing executions |
Next: Reducing variables, Up: Less information per file [Contents][Index]
Here are ways to compute invariants over a subset of the program points (functions) in your program.
trace-purge-fns.pl script takes as
arguments a (Perl) regular expression and a list of files. It
modifies each file in place, removing every program point (function)
whose name matches the regular expression. The -v flag means
to retain rather than discard matching program points. For instance,
to create two subparts of a .dtrace file — one containing the
getters and setters, and the other containing all other functions —
use the following commands:
cp myprog.dtrace myprog-setters.dtrace trace-purge-fns.pl -v 'set|get' myprog-setters.dtrace cp myprog.dtrace myprog-non-setters.dtrace trace-purge-fns.pl 'set|get' myprog-non-setters.dtrace
Also, the configuration variable daikon.Daikon.ppt_perc allows a percentage of the program points to be processed. See General configuration options, for details.
Next: Reducing executions, Previous: Reducing program points, Up: Less information per file [Contents][Index]
Here are ways to compute invariants over a subset of the variables in your program. This changes the resulting invariants, because invariants over the missing variables (including any relationship between a missing variable and a retained variable) are not detected or reported. For instance, you might remove uninteresting variables (or ones that shouldn’t be compared to certain others) or variables that use a lot of memory (such as some arrays).
trace-purge-vars.pl script. Analogously to the
trace-purge-fns.pl script, it removes certain variables from
all program points in a function (or retains them, with the
-v flag). After running this command, you will need
to edit the corresponding .decls file by hand to remove the
same variables.
Previous: Reducing variables, Up: Less information per file [Contents][Index]
Here are ways to run Daikon over fewer executions of each program point. (You cannot combine the resulting invariants in order to obtain the same result as running Daikon over all the executions.)
daikon/scripts/trace-untruncate program to remove the last,
possibly partial, record from the file:
trace-untruncate myfile.dtrace
modifies myfile.dtrace in place to remove the last record.
Alternately, you can use the
daikon/scripts/trace-untruncate-fast program. It operates much
faster on very large files. In order to use
trace-untruncate-fast, you must have already compiled it
(see Installing Daikon).
Next: Reporting problems, Previous: Large dtrace files, Up: Troubleshooting [Contents][Index]
Before reporting or investigating a problem with Chicory, always check that the program executes properly when not being run under Chicory’s control.
For example, if a command such as
java -cp myclasspath:${DAIKONDIR}/daikon.jar daikon.Chicory \
DataStructures.StackArTester args...
fails with an error, then first try
java -cp myclasspath:${DAIKONDIR}/daikon.jar DataStructures.StackArTester args...
| • BCEL must be in the classpath | ||
| • ClassFormatError LVTT entry does not match | ||
| • Attempted duplicate class definition error |
If Chicory throws one of the following errors:
BCEL must be in the classpath. Normally it is found in daikon.jar. couldn't find or load main class
then the problem is most likely that the classpath does not contain daikon.jar.
Next: Attempted duplicate class definition error, Previous: BCEL must be in the classpath, Up: Chicory problems [Contents][Index]
If Chicory throws an error such as the following:
Exception in thread "main" java.lang.ClassFormatError: LVTT entry for 'v' in class file javautil/ArrayList17 does not match any LVT entry
then the problem is most likely that the classpath contains a version of the BCEL library that is newer than the 6.0 release. A modification was made to Apache BCEL after the 6.0 release that causes this problem. The incompatible version might appear in bcel.jar, in Java’s rt.jar, or elsewhere. You should either remove that version of BCEL from the classpath, or you should ensure that it appears after daikon.jar, which contains the correct version of BCEL. (If you are running Daikon from sources rather than from daikon.jar, then ensure that ${DAIKONDIR}/java/lib/bcel.jar is the first version of BCEL on the classpath.)
Previous: ClassFormatError LVTT entry does not match, Up: Chicory problems [Contents][Index]
If Chicory throws an error such as the following:
Exception in thread "main" java.lang.LinkageError: java.lang.LinkageError: loader (instance of sun/misc/Launcher$AppClassLoader): attempted duplicate class definition for name: "SquarePanel"
then the problem is most likely that some method in your program uses
Java runtime services to set up an additional thread that can get
invoked asynchronously. One example is using the java.lang.SecurityManager
class to set up a SecurityManager via System.setSecurityManager. The easiest
way to work around this is to use the --ppt-omit-pattern option to Chicory.
After you have located the problem method, rerun Chicory with the additional
option:
--ppt-omitpattern=MyPackage.MyProblemMethod
Next: Further reading, Previous: Chicory problems, Up: Troubleshooting [Contents][Index]
If you find a bug, want to request a new feature, or have a suggestion to improve Daikon or its documentation, open an issue at https://github.com/codespecs/daikon/issues. (If you can’t figure out how to do something or do not understand why Daikon works the way it does, that is a bug, too — in the Daikon documentation. Please report those as well.) We will try to assist you and to correct any problems, so please don’t hesitate to ask for help or report difficulties. Additionally, if you can contribute enhancements or bug fixes, those will be gratefully accepted. If you have a question about the source code of Daikon or Kvasir, send email to daikon-developers@googlegroups.com.
In order for us to assist you, please provide a complete and useful bug report. Your bug report must provide all the information that is required in order to replicate the bug and verify that our fix corrects the problem. If you do not provide complete information, we will not be able to assist you.
Your bug report should include:
When users provide an inadequate bug report, it is frequently more difficult for us to reproduce an error than to correct it. If you make it easy for us to reproduce and verify the problem, then it is much more likely to be corrected. Thanks for helping us to help you!
You may also wish to take advantage of the Daikon mailing lists (see Mailing lists).
Previous: Reporting problems, Up: Troubleshooting [Contents][Index]
More information on Daikon can be found in the Daikon Developer Manual (see Introduction in Daikon Developer Manual). For instance, the Daikon Developer Manual indicates how to extend Daikon with new invariants, new derived variables, and front ends for new languages. It also contains information about the implementation and about how to debug.
You may find discussions on the mailing lists (see Mailing lists) helpful. The mailing list archives may contain helpful information, but we strive to incorporate that information in this manual so that you don’t have to search the archives as well.
For further reading, see the list of publications at the Daikon homepage, http://plse.cs.washington.edu/daikon/pubs/.
Next: General Index, Previous: Troubleshooting, Up: Top [Contents][Index]
The Daikon invariant detector is named after an Asian radish. “Daikon” is pronounced like the combination of the two one-syllable English words “die-con”.
More information on Daikon can be found in the Daikon Developer Manual (see Introduction in Daikon Developer Manual). For instance, the Daikon Developer Manual indicates how to extend Daikon with new invariants, new derived variables, and front ends for new languages. It also contains information about the implementation and about debugging flags.
| • History | ||
| • License | ||
| • Mailing lists | ||
| • Credits | ||
| • Citing Daikon |
This manual describes Daikon version 5.8.24, released May 6, 2026. A more detailed list of revisions since mid-2001 can be found in file doc/CHANGELOG.md in the distribution; this section gives a high-level view of the package’s history.
There have been four major releases of Daikon, with different features and capabilities. User experiences and technical papers should be judged based on the version of Daikon current at the time of use.
Daikon 1 was written in the Python programming language in 1998. It included front ends for C, Java, and Lisp. The C front end was extremely limited and failed to operate correctly on all C programs: sometimes it suffered a segmentation fault while instrumenting a target program, and even when that did not happen, sometimes the instrumented program segmentation-faulted while running. The Lisp front end operated correctly on all Lisp programs, but only instrumented certain common constructs, leaving other language features uninstrumented. The Java front end was reasonably reliable. The Lisp front end instrumented procedure entries, exits, and loop heads; the C front ends instrumented only procedure entries and exits; and the Java front end instrumented program points for object invariants as well as procedure entries and exits. Daikon 1 and its Lisp front end were only removed from Daikon version control repository in November 2010, though they had long been obsolete.
Daikon 2 was a complete rewrite in the Java programming language and was the first version to contain a substantive manual. Daikon 2 uses the same source-based Java front end as did Daikon 1, though with certain enhancements. Its C front end was rewritten from scratch; it instruments only procedure entries and exits. A front end also exists for the Input Output Automaton programming language, but is not included in the Daikon distribution.
Daikon 3 is a redesign of the invariant detection engine to work incrementally — that is, to examine each sample (execution of a program point) once, then discard it. By contrast, Daikon 1 and Daikon 2 made multiple passes over the data. This simplified their algorithms but required storing all the data in memory at once, which was prohibitive, particularly since data trace files may be gigabytes in size. Daikon 3 also introduces the idea of a dataflow hierarchy, a way to relate and connect program points based on their variables.
Daikon 4 includes new binary front ends for Java and for C. These front ends make Daikon much easier to use. Daikon 4 makes .decls files optional; program point declarations are permitted to appear in .dtrace files. Daikon 4 is released under more liberal licensing conditions that place no restrictions on use.
Daikon 5 adds a new front end (Celeriac) for .NET languages (C#, F#, and Visual Basic). The underlying Valgrind was updated and much work done to ensure Daikon works properly on the latest versions of Linux. The Chicory front end for Java was modified to support Java 7. Daikon releases were moved from MIT to the University of Washington. The bug tracker was moved to Google Code, and mailing lists moved to Google Groups.
Next: Mailing lists, Previous: History, Up: Details [Contents][Index]
Copyright © 1998-2025
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
The names and trademarks of copyright holders may not be used in advertising or publicity pertaining to the software without specific prior permission. Title to copyright in this software and any associated documentation will at all times remain with the copyright holders.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NON INFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
| • Library licenses | ||
| • Front end licenses |
Next: Front end licenses, Up: License [Contents][Index]
| • getopt license | ||
| • JUnit license |
Next: JUnit license, Up: Library licenses [Contents][Index]
Daikon uses the Java port of the GNU getopt library, which is copyright 1998 Aaron M. Renn. The getopt library is free software, and may be redistributed or modified under the terms of the GNU Library General Public License version 2. A copy of this license is included with the Daikon distribution as the file doc/gnu-gpl-2.txt.
Previous: getopt license, Up: Library licenses [Contents][Index]
Daikon’s unit tests use the JUnit testing framework, which is governed
by the Common Public License, version 1.0. JUnit is provided on an
“as is” basis, without warranties or conditions of any kind, either
express or implied including, without limitation, any warranties or
conditions of title, non-infringement, merchantability or fitness for
a particular purpose. Neither the Daikon developers nor the authors of
the JUnit framework shall have any liability for any direct, indirect,
incidental, special, exemplary, or consequential damages (including
without limitation lost profits), however caused and on any theory of
liability, whether in contract, strict liability, or tort (including
negligence or otherwise) arising in any way out of the use or
distribution of JUnit or the exercise of any rights granted in
the Common Public License, even if advised of the possibility of such
damages. Those portions of JUnit that appear in the Daikon
distribution may be redistributed under the same terms as Daikon
itself; this offer is made by the Daikon developers exclusively and
not by any other party. The Common Public License is included with the
Daikon distribution as the file java/junit/cpl-v10.html.
Previous: Library licenses, Up: License [Contents][Index]
Note that the front ends discussed in this manual are separate programs, and some are made available under different licenses. Because the front ends are separate programs not derived from the Daikon invariant detection tool, you are neither required nor entitled to use the Daikon invariant detector itself under these other licenses.
| • dfepl license | ||
| • Kvasir license | ||
| • Celeriac license |
Next: Kvasir license, Up: Front end licenses [Contents][Index]
The Daikon Perl front end dfepl may be used and distributed under the
regular Daikon license or, at your option, either the GNU General
Public License or the Perl Artistic License (that is, under the same
terms as Perl itself).
Next: Celeriac license, Previous: dfepl license, Up: Front end licenses [Contents][Index]
The Daikon C/C++ front end Kvasir is based in part on the Valgrind
dynamic program supervision framework, copyright 2000-2004
Julian Seward, the Sparrow Valgrind tool, copyright 2002
Nicholas Nethercote, the MemCheck Valgrind tool,
copyright 2000-2004 Julian Seward, the
readelf program of the GNU Binutils, copyright 1998-2003 the Free
Software Foundation, Inc., the GNU C Library, copyright 1995, 1996,
1997, 2000 the Free Software Foundation, Inc., and the Diet libc,
copyright Felix von Leitner et al. Kvasir is free software; you can
redistribute it and/or modify it under the terms of the GNU General
Public License as published by the Free Software Foundation; either
version 2 of the License, or (at your option) any later version.
Kvasir is distributed in the hope that it will be useful, but WITHOUT
ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License
for more details. You should have received a copy of the GNU General
Public License along with Kvasir, in the file kvasir/COPYING;
if not, write to the
Free Software Foundation, Inc., 51 Franklin St., Fifth Floor, Boston, MA
02110-1301, USA.
Previous: Kvasir license, Up: Front end licenses [Contents][Index]
The Daikon .NET front end Celeriac is Copyright © 2012 by Kellen Donohue. Portions of Celeriac are covered by the Microsoft Public License, this is at the top of every such file. Otherwise the following license is in effect:
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NON-INFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
The following mailing lists (and their archives) are available:
A low-volume, announcement-only list. For example, announcements of new releases are sent to this list. To subscribe, visit https://groups.google.com/forum/#!forum/daikon-announce.
A moderated list for the community of Daikon users. Use it to share tips and successes, and to get help with questions or problems (after checking the documentation). To subscribe, visit https://groups.google.com/forum/#!forum/daikon-discuss.
This list goes to the Daikon maintainers. Use it for questions about the Daikon and Kvasir source code. Use the issue tracker (https://github.com/codespecs/daikon/issues) for bug reports and feature requests. If you are an active contributor to Daikon, you may send mail to the list asking to be added to the list.
Do not send the same message to multiple mailing lists. Doing so is antisocial: it causes confusion and extra work. If you do so, your question will not be answered.
Next: Citing Daikon, Previous: Mailing lists, Up: Details [Contents][Index]
The following individuals have contributed to Daikon: Alan Donovan, Alan Dunn, Alexandru Salcianu, Allen Liu, Antonio Garcia-Dominguez, Benjamin Morse, Brian Demsky, Carlos Pacheco, Cemal Akcaba, Charles Tam, Charlie Garrett, Chen Xiao, Danny Dig, Darko Marinov, David Cok, David McArthur, David Notkin, Derek Rayside, Dieter von Holten, Emily Marcus, Eric Fellheimer, Eric Spishak, Florian Gross, Florian S. Gross, Forrest Coward, Galen Pickard, Greg Jay, Greg Sullivan, Gustavo Santos, Iuliu Vasilescu, Jaime Quinonez, Jake Cockrell, James Anderson, Javier Thaine, Jeff Perkins, Jeff Yuan, Jelani Nelson, Jeremy Nimmer, Jonathan Burke, Josh Kataoka, Kathryn Shih, Kellen Donohue, Konstantin Weitz, Laure Thompson, Lee Lin, Mark Roberts, Massimiliano Menarini, Matthew Tschantz, Melissa Hao, Michael Ernst, Michael Harder, Nii Dodoo, Philip Guo, Robert Rudd, Ryan Newton, Samir Meghani, Sandra Loosemore, Stephen Garland, Stephen McCamant, Sung Kim, Suzanne Millstein, Tao Xie, Tatyana Nikolova, Todd Schiller, Toh Ne Win, Vikash Mansinghka, Vincent Hellendoorn, Weitian Xing, Werner Dietl, William Griswold, Yoav Zibin, Yuriy Brun.
Craig Kaplan carved the Daikon logo.
The feedback of Daikon users has been very valuable. We are particularly grateful to B. Thomas Adler, Rich Angros, Tadashi Araragi, Seung Mo Cho, Christoph Csallner, Dorothy Curtis, Juan Pablo Galeotti, Diego Garbervetsky, Mangala Gowri, Madeline Hardojo, Engelbert Hubbers, Nadya Kuzmina, Scott McMaster, Charles O’Donnell, Alex Orso, Rodric Rabbah, Manos Renieris, Rosie Wacha.
Many others have also been generous with their feedback, for which we are also grateful.
If your name has been inadvertently omitted from this section, please let us know so we can correct the oversight.
Financial support has been provided by: National Science Foundation (NSF), Defense Advanced Research Projects Agency (DARPA), ABB, Edison Design Group, IBM, NTT, MIT Oxygen Project, Raytheon, Toshiba.
If you wish to cite Daikon in a publication, we recommend that you reference one of the scholarly papers listed at http://plse.cs.washington.edu/daikon/pubs/#invariant-detection in lieu of, or in addition to, referencing this manual and the Daikon website (http://plse.cs.washington.edu/daikon/).
| Jump to: | -
.
/
6
:
@
[
A B C D E F H I J K L M N O P R S T U V W X |
|---|
| Jump to: | -
.
/
6
:
@
[
A B C D E F H I J K L M N O P R S T U V W X |
|---|